
8. Informationswissenschaft als Brückenwissenschaft
Approaches to sense disambiguation with respect to automatic indexing and machine translation
6. The semantic (text) knowledge approach
Heinz-Dirk Luckhardt
classification and thesauri and their use in NLP
CONTENTS of this Chapter
- Applications for Classifications
- Thesauri and their Possible Use in MT and Automatic Indexing
- What can Mono- or Multilingual Thesauri Achieve?
- List of Thesaurus Relations Used in this Paper
Classifications and thesauri are document description languages i.e. they are used to add a kind of content description to documents that can be used later on to retrieve these documents in a document collection. There is an obvious relation to the processing of natural language: both languages are used to describe natural language text, and thesauri above this consist of natural language expressions themselves. Already their generation and their handling is an example for ’natural language processing‘.
In addition to this, especially thesauri have some properties that predestinate them for applications in natural language systems in the field of automatic indexing and machine translation: they can be used to define terms unambigously and to set up semantic relations. This can be interesting because it is the ambiguity of words or larger linguistic units (groups of words, parts of sentences) that makes the processing of natural language texts so difficult.
To illustrate the argument, here are some examples for ambiguities:
(1) ... Randeffekte ausschalten ...
(to eliminate / switch off side effects)
(2) ... die Bildung von Keimen ...
(the formation / education of germs)
(3) ... im Verlauf von Walzen und Wärmebehandlung
... (in the course ofrolling/roller and heat treatment
(4) ..., während der Kern konvektiv erhitzt wird ...
(while the core/kernel/grain is heated up convectively)
(5) Abwasserabgabe
[sewage charge, sewage discharge]
(6a) Während des Betriebs der Anlage nicht rauchen.
(No smoking during operation of the plant)
(6b) Nicht rauchen, während die Anlage läuft.
(No smoking while the plant is in operation)
(7) Singular Plural
________________________________
--- Vortrag ----- Vorträge
paper --- Aufsatz ----- Aufsätze
--- Papier ----- -
--- - ----- Ausweispapiere
Ambiguities (cf. the words in bold/italic in the German sentences) can be tackled in different ways (cf. Luckhardt 1987). The simplest criteria are morphological, like in (7). One of the four readings can be eliminated by means of the number property: ‚paper‘ as a singular excludes the reading ‚Ausweispapiere‘ and paper in plural excludes the reading ‚Papier‘.
By syntactic analysis ambiguities like (6) will normally be solved, i.e. the application of grammatical rules should automatically lead to the recognition of ‚während‘ in (6a) as preposition and in (6b) as subordinating conjunction. Syntacto-semantic criteria may be applied in cases like (1) where the semantic category of specific verb arguments plays a part. If ‚ausschalten‘ is to be translated by ’switch off‘, the direct object must carry the semantic class ‚concrete‘. For an ‚abstract‘ object ‚eliminate‘ would be appropriate.
All these criteria belong to the field of linguistic analysis which determines linguistic structures on word, sentence, and text level, captures them in an appropriate representation and eliminates ambiguities on this basis. Thus in the example below the noun reading of the first word (‚Trotz‘) is eliminated, because no valid reading can be found for this sentence with a noun in this place, as the verb has no free valency for it. Thus the reading ‚preposition‘ remains.
TEXTWORTFORM WKL LEMMANAME STW ------------------------------------------------------------- Trotz PRP TROTZ FWK der ARTB D- (ARTB) FWK schwierigen ADJ SCHWIERIG ADJ konjunkturellen ADJ KONJUNKTURELL ADJ Rahmenbedingungen SUB /RAHMEN/BEDINGUNG SUB erhoeht FIV ERHOEHEN VRB sich PER ER/SIE/ES/SIE (REF)FWK das ARTB D- (ARTB) FWK Ergebnis SUB ERGEBNIS SUB gegenueber PRP GEGENUEBER (PRP) FWK dem ARTB D- (ARTB) FWK Vorjahr SUB VORJAHR SUB
This kind of analysis sooner or later ends at a barrier beyond which ‚knowledge‘ about the domain of the text is needed. These barriers cannot be determined easily, as one can see from examples (2) and (3). ‚Keime‘ cannot have an (e.g. university) education, as the human reader of the text ‚knows‘. The computer can at best produce two linguistic analyses: one where ‚Keim‘ is the object of the action verb ‚bilden‘, and another where ‚Keim‘ carries the property ‚Bildung‘.
Here we need an analysis of compatibility which verifies or falsifies the linguistic structures on the basis of knowledge about the text domain, i.e. knowledge about what or who may or may not have ‚Bildung‘ / ‚education‘. But linguistic structures we do need here, because they represent the links between the concepts without which the concepts would be just a list.
The like can be said about (3): ‚Walzen‘ will not appear ambiguous to the human reader, as after reading ‚im Verlauf‘ (‚in the course of‘) he or she is conditioned for expecting a noun of action or a time span. The computer will produce one reading with ‚Walze‘ (= roller) as an object and one with ‚Walzen‘ (= rolling) as an action. The first reading which is syntactically correct can only be eliminated using domain knowledge.
These are some examples for the necessity of domain knowledge of the analysed text and its context in whatever form this knowledge may be available. I will now turn to the question whether and inhowfar classifications and thesauri may be used as forms of knowledge representation for this purpose.
Application of classifications
I have chosen the International Patent Classification (IPC) as an example because we have carried out a number of projects in cooperation with the German Patent Office (Deutsches Patentamt) that were based on the IPC. (see Luckhardt/Zimmermann 1991). Also there are large text collections that could serve as a test bed, if need be.
We shall regard a cut through the IPC comprising alle subdivisions, i.e. going down to the subgroup level. The bottom level of the following hierarchy is formed by two subgroups that contain the word ‚pin‘ representing two different concepts:

On the first glance, the following scenario looks ideal: a text to be translated or indexed is classified according to the same detailed classification as the entries in the computer lexicon used for morpho-syntactic analysis. Thus the English word ‚pin‘ is unambiguously translated by ‚Sperrstift‘ or ‚Kegel‘, if the text belongs to the respective subgroups. Similarly, in multilingual indexing the appropriate unambigous terms could be assigned.
This ‚ideal‘ case isn’t ideal in several respects:
1. This would only allow the translation/indexing of patents, as only patent texts are classified and classifiable in this way, and the IPC refers only to objects relevant in the field of patents. This, however, would not suffice as an excluding criterion as there is a huge demand for patent translations, and an MT system or automatic indexing system only for patents would surely pay off.
2. Even for this restricted application an unambiguous assignment of a text to one class (on the main or subgroup level) is not always possible. Patents are mostly assigned several classes, as for every patent one IPC main class and several secondary classes are assigned.
3. Even if we accept 1. and 2., there still remains the problem of assigning the different equivalents their detailed classes, i.e. of distinguishing between the different readings of a word by means of the classes in the computer lexicon. This can intellectually hardly be managed. It may be done by (semi-)automatic methods, i.e. by comparing between the German and English version of the IPC.
4. What would be the result of such a procedure? A huge and hardly manageable dictionary, for many ambiguous terms would occur in hundreds of main groups, and this – if one would use the whole classification – would have to be entered into the lexicon in one way or the other. Such an automatically built lexicon would probably be too big for intellectual maintenance.
5. By such a procedure, the lexicon would also be blown up because in the different language versions of the IPC the same concepts are not always given the same names. Where, e.g., in the German version the term ‚Ballenpresse‘ is used, the English version uses ‚baler‘ or ‚baling press‘. Cases like these call for a thesaurus, of course.
The classification should not be too detailed, because – even on the level of the IPC classes like A62 or C01 – there are too many problems of not knowing whether to assign a term to this class or to another, i.e. there are still too many overlappings. ‚Backöfen‘ (= ovens), e.g., are treated in four different classes.
If we follow this argumentation, we shall have to try to abstract from the very detailed classification without loosing too much of its differentiating potential, i.e. if we choose classes that are too coarse, too many equivalents fall into the same class and can no longer be differentiated.
So, a classification that can be used for MT may lie between the class level and the subsection level. This is where for MT systems like SYSTRAN or SUSY the classification level has been assumed (also: EURODICAUTOM). This may be illustrated by the following classification used for the STS project:
A00 General B00 Humanities C00 Society / Sociology ... K00 Materials K10 Glass and ceramics K20 Metallurgy K30 Wood K40 Cement ...
Thesauri and their possible use in NLP (MT and automatic indexing)
I want to take a look at the thesaurus idea from the viewpoint of automatic language processing and discuss the usefulness of thesauri: why should one think about using thesauri as they, e.g., are described in DIN 1463 (German Industrial Standard) in MT?
1. Reduction of ambiguity
The terms used in thesauri must be unambiguous. This may be achieved by referring from ambiguous terms to unambiguous ones:
Eiweiß USE Eiklar
Eiweiß USE Protein
("a USE b" means: "use b for a")
or by marking homonyms / polysemes:
Kiefer (Knochen) Kiefer (Nadelholz) Kiefer (Baum) Knie (Körperteil) Knie (Formstück)
These are notational aids, necessary prerequisites for the assignment of translational equivalents e.g. in a translational dictionary, but not criteria for disambiguation. These may be expected from the 2nd aspect:
Illustration of the concepts polysemy/homonymy/synonymy
| SOUND | SOURCE | MEANING | EXAMPLE | |
| Homonymy | equal | unequal | uneqal | ‚bark‘ |
| Polysemy | equal | equal | unequal | ‚type‘ |
| Synonymy | unequal | – | equal/similar | ‚peasant/farmer‘ |
2. Linking related concepts
‚There is a basic necessity to mark the relations between concepts or their denominations in a thesaurus. Thus, in a certain way the relations between a descriptor and other denominations (…) represent a definition of this descriptor, as they show its place in the semantic framework.‘
‚Grundsätzlich ist es notwendig, in einem Thesaurus die zwischen Begriffen bzw. ihren Bezeichnungen bestehenden Relationen kenntlich zu machen. Auf diese Weise vermitteln die Beziehungen eines Deskriptors zu anderen Bezeichnungen (…) in gewisser Weise eine Definition des Deskriptors, da es seinen Ort im semantischen Gefüge aufzeigt.‘
(DIN 1463, 5)
There are three kinds of relation:
a) Relation of equivalence which marks two terms as equivalent:
Heirat USE Eheschließung marriage USE wedding Recherche USE Retrieval
b) Relation of hierarchy, with the following distinction:
Relation of abstraction (generic relation)
NTG = NARROWER TERM (GENERIC)
BTG = BROADER TERM (GENERIC)
motor vehicle NTG passenger car lorry BTG motor vehicle
Partitive relation
NTP = NARROWER TERM (PARTITIVE)
BTP = BROADER TERM (PARTITIVE)
car NTP motor car body BTP car
c) Associative relation (RT for RELATED TERM) which in a way links related concepts between which no other relation can be named. This includes a lot of relationships:
Determinatum – Determinans:
animal nutrition RT animal
Same hierarchical level:
Bavaria RT Hesse yolk RT white of egg white of egg RT egg-shell
Antonymy:
heat RT cold
Sequential relation:
father RT son
Affinity:
book RT reading
Thesauri have been developed for a multitude of special fields and applications. Can they be used for the MT of texts from these special fields?
A thesaurus serves for ‚indexing, storing and retrieval in a documentation field‘ (‚…dient in einem Dokumentationsgebiet zum Indexieren, Speichern und Wiederauffinden‘ (DIN 1463, 2). This purpose leads to some problems for the use of existing thesauri developed for documentation purposes, in MT:
1. A thesaurus always covers just a small part of the lexicon, as it contains only ‚relevant‘ terms as descriptors (they are used for retrieval) and non-descriptors (they are not used for retrieval, but refer to a descriptor to be used in their place), For MT, a thesaurus must contain all words to be disambiguated or to be used for disambiguating other words.
2. In traditional thesauri, e.g. verb and noun / activity and result of this activity / activity and instrument are set equivalent without stating the exact relation between them. For translation, this is inadequate:
Wohnen USE Wohnung Walzen USE Walze
3. Descriptors sometimes are not distinguished according to their basic concepts. The European Union’s EUROVOC thesaurus, e.g., uses the descriptor BEIZE although there are quite different concepts behind it (medium vs. action: etching, staining, mordant, stain, bate, pickle; hawking/falconry).
4. There is a general question: what use can MT make of thesaurus relations that in the first place are meant for information condensation, whereas MT strives for one-to-one mapping of source language text onto target language text? Can they be used to build up an associative net? Some examples from EUROVOC:
Beratungsbüro USE Engineering Beize USE Schleifmittel Kleinrechner USE Computer Kiwi (Frucht) BROADER TERM tropische Frucht Berufliche Eignung BROADER TERM Arbeitskräfte
I shall come back to these questions later.
5. Some thesaurus terms will never occur in real texts, because they have only been introduced to subsume concepts. There must, however, be a direct connection between thesaurus and text in order to make a thesaurus usable in MT. An example: a descriptor like ‚Beförderung zu Lande und zu Wasser‘ (= transport by land and by water) will rarely occur in texts. It has been included in the EUROVOC thesaurus in order to subspecify ‚Beförderungsart‘ (= mode of transport). A similar example is ‚Leben in der Gesellschaft‘ / ‚Soziale Fragen‘ (living in society / social questions). And ‚Transport über Rohr‘ (= transport by pipeline) is only meant to give that node a name that combines ‚Gasfernleitung‘ (=gas pipeline) and ‚Ölfernleitung‘ (= petrol pipeline), To sum up this argument: to be usable for MT a thesaurus should only contain terms really occurring in texts that have to be disambiguated or serve to disambiguate others.
All these problems suggest that (monolingual) thesauri that have been compiled for documentation purposes can only in part be used for MT and probably also for automatic indexing. In general there are a number of open questions that need further investigation:
1. Inheritance/propagation of property values? Can property values be transfered between entries of a thesaurus in that sense that narrower terms inherit all values from broader terms, as we know it from knowledge representation in AI? Surely not for existing thesauri, if they contain BROADER TERM relations to denominate a general notion of superordination (cf. ‚Berufliche Eignung‘ BROADER TERM ‚Arbeitskräfte‘). In any case, such inheritance mechanisms might be interesting for a further semantic analysis.
2. What kind of relations do we need? For MT we should distinguish between two kinds:
a. general ones, i.e. those that serve for building a semantic net
b. those used for assigning translation equivalents (TR)
Associative relations, e.g., participate in building a semantic net, but they are not used between terms that are (translational) equivalents of each other:
Bienenzucht RT Honig
‚Bienenzucht‘ (= apiculture) has to do with ‚Honig‘ (= honey), but the two terms cannot be used as synonyms or quasi-synonyms. A narrowly defined USE relation, however, can link two terms that correspond to the same concept, i.e. which are synonyms of each other and which play a role in assigning a translation, e.g.:
Band USE Fließband line USE assembly line Fließband TR assembly line assembly line TR Fließband Bekleidung USE Kleidung clothes USE clothing Kleidung TR clothing clothing TR Kleidung
The USE relation here would be something like a disambiguation relation: in a specific context that is determined by the text context and the subject field a vague term is assigned an unambiguous one that stands for a specific concept, for that an unambiguous translational eqivalent exists, which may be used for the above ambiguous term.
We shall discuss later in more detail what relations may be used.
3. The technical organization of such a thesaurus cannot be discussed here.The thesaurus will be built up by linking two terms with a relation and collecting the resulting constructs in a database. How the resulting semantic web (see example below) is represented and used is another point of discussion.
What can mono- or multilingual thesauri achieve?
Thesauri serve ‚for indexing, storage, and retrieval in a field of documentation (‚… dienen in einem Dokumentationsgebiet zum Indexieren, Speichern und Wiederauffinden‘, DIN 1463), multilingual thesauri serve for ’simplifying the information flow across language barriers‘ (‚… dienen der Vereinfachung des Informationsflusses über Sprachbarieren hinweg‘). A multilingual thesaurus lists equivalences between terms of the languages involved – a basic prerequisite for its use in MT.
This does not mean, however, that a multilingual thesaurus is in any case immediately usable in MT. Problems arise
1. if source language compounds have as their target language equivalent a combination of terms:
solar heating - [chauffage, energie solaire]
2. if the conceptual scope of a word is restricted by definitions or scope notes without any explanation how this restriction comes about, i.e. the computer cannot use such a relationship in the course of NL analysis and translation if it is not introduced by a rule. We shall come back to this aspect later:
Ablauf (Abfluß) TR discharge Ableiter (Abfluß) TR discharge Abfall (Müll) TR refuse skidding (forwards) TR Rutschen skidding (sideways) TR Schleudern
The text, e.g. contains the word ‚Ablauf‘. How is the computer to discern between the different readings differentiated by an expression in brackets? The examples are notations for which disambiguation rules still have to be formulated.
skidding (forwards)
skidding <
skidding (sideways)
3. if by synonym control
verb and noun,
activity and result, or
activity and Instrument
are combined to form a pair of synonyms without stating the exact relation between the two:
Wohnen - Wohnung Walzen - Walze
4. In English terms are often given in plural form. This is an additional problem when comparing thesaurus terms and text words. As a rule, basic forms will have to be used, not inflected words.
A thesaurus which is organized in the way described above is first of all only another form of translation dictionary with unambiguous relationships. We shall now turn to the question how a (monolingual) thesaurus can be used for disambiguation.
As a principle, the ambiguities and vagueness of natural language in the word material collected for the construction of a thesaurus is eliminated in the thesaurus itself (Burkart 1990, 166), but in a text to be translated, of course, they are still there. How can text and thesaurus come together?
1. By restricting the thesaurus to an area where there are little or no ambiguities (however realistic this may be)?
Thus source language terms which are ambiguous in normal language use could be assigned definite target language expressions:
Band USE Magnetband Magnetband TR magnetic tape
or in a different thesaurus:
Band USE Fließband Fließband TR assembly line
A direct assignment
Band - tape and Band - line
would be better, as explications like ‚Band => magnetic tape‘ and ‚BAND => assembly line‘ are not justified if we do not take the context into account. For this simple assignment, however, that consists of just a pair ’source language equivalent / target language equivalent‘ we do not need a thesaurus, of course.
2. A thesaurus will be useful in those cases where we succeed in building up a relationship between the domain the thesaurus describes and the text to be translated.
In other words: we have to set up a scenario where on the basis of the thesaurus a text context which on the surface has lots of ambiguities can be clarified in such a way that unwanted readings are filtered out and per text word the correct reading is adopted. This is exactly what computational linguistics dreams of, and surely I can only sketch a possible scenario in what follows.
The field that we touch here is heavily investigated by artificial intelligence, cognitive linguistics and computational linguistics: the representation of knowledge in neural networks that are assumed to be the underlying knowledge structure in the human brain. I want to restrict my considerations to a very elementary level, i.e. to the interaction of thesaurus relations in connection with the resolution of ambiguities in machine translation and multilingual indexing.
For our purpose, one can imagine the knowledge base for MT as a system of thesauri – one per subject field – where for every processed text one thesaurus or a number of thesauri are activated that are weighted according to their relevance for the subject field. This may be done by a simple subject field code which is assigned to the text.
Example: the translation of the German word ‚Band‘:
Isolierband - tape Tonband - tape Zielband - tape Armband - bracelet (Leder-)band - strap (Schuh-)band - lace (Farb-)band - ribbon (Faß-)band - hoop (Säge-)band - band (Förder-)band - belt (Fließ-)band - line Band (Architektur) - bond Band (Metallver.) - strip Band (Anatomie) - ligament Band (Radio) - band Band (Buch) - volume Bände - volumes<
There is hardly a case where exactly one equivalent can be assigned:
subject field equivalent textile industry ribbon sports tape jewellery bracelet computers [ribbon,tape] automobile construction [tape,strip,line]
Let us assume there are potentially three readings of ‚Band‘ in automobile construction:
Band USE Isolierband (insulating tape) Band USE Metallband (metal strip) Band USE Fließband (assembly line)
There are further relations like:
Elektromaterial NTG Isolierband Elektromaterial NTG Kabel Rohmaterial NTG Metallband Fertigungsstraße USE Herstellungsstraße Fertigungsstraße NTP Fließband
The following text is to be translated:
‚Diese Qualitätskontrolle liefert die Ergebnisse rascher und mit höherer Aussagefähigkeit, so daß auch schnellere Rückkopplung und damit Verbesserungen an der Herstellungsstraße möglich sind. Zum Abtasten der Oberflächen werden Laserstrahlen benutzt, da dieses System weniger empfindlich gegenüber ungenauer Positionierung ist. Da die Überwachung am laufenden Band erfolgen muß, wurde der speziell dafür konzipierte Puma 760 ausgewählt. Am Band wird zunächst der jeweilige Autotyp identifiziert …
During the automatic analysis of the text – on the basis of the underlying thesaurus – a text knowledge structure is built up that represents at the same time the text terms and the corresponding thesaurus terms and their relations:
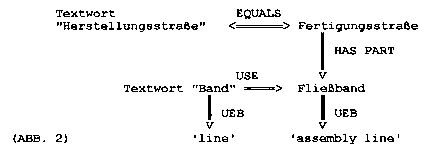
The thesaurus relations can be employed to build up a semantic net where ‚Herstellungsstraße‘ and ‚Band‘ are related to each other, i.e. ‚Band‘ = ‚Fließband‘, but not = ‚Tonband‘ or = ‚Meßband‘. The reading ‚Fließband‘ for ‚Band‘ is activated by ‚Herstellungsstraße‘, and thus the definite translation ‚(assembly) line‘. In fig. 3 is shown how this substructure is embedded into the larger structure: the bold nodes represent the activated substructure, the rest is also valid, but with a lower weight. This is hopefully achieved by giving the RT relations a lower weight in comparison to relations like NTP or USE. Also, the nodes Band_2 (not represented in the figure) and Band_3 are embedded deeper into the structure with respect to the initializing node ‚Herstellungsstraße‘, as there is one more node in between (‚Rohmaterial‘ and ‚Elektromaterial‘).
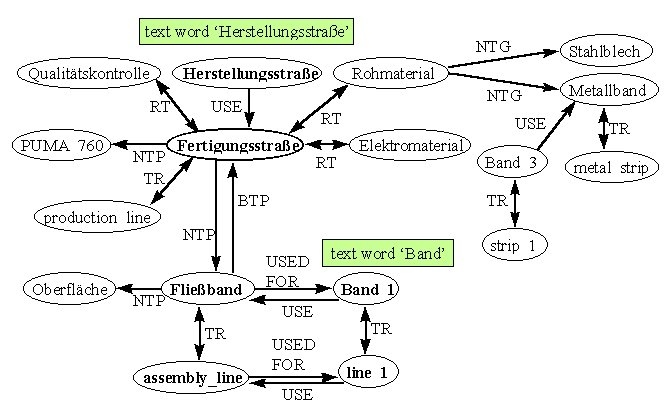 (fig. 3)
(fig. 3)
These considerations pose a number of questions which only a successful implementation could answer:
1. Not only the terms of the field ‚automobile construction‘ are ambiguous, but also general words or words from other subject fields (‚empfindlich‘, ‚Überwachung‘, ‚am laufenden Band‘, ‚Abtasten‘). The correlation between thesauri has to be clarified, and also the criteria for selecting thesauri for a text.
2. Also the cooperation between different methods of disambiguation have to be determined. Basically thesauri are employed, when syntacto-semantic criteria have removed as many ambiguities as possible, for these criteria work best, i.e. as a rule they are safer.
3. The biggest problem will be that too many too vague relations are set up for a text or part of a text. How can one make sure that as many relevant and as little irrelevant relations as possible are built up? There are a number of criteria for setting up weights for relations or for paths in the semantic net built:
a. by letting relations ‚age‘ , i.e. the weight of relations is reduced as new sentences are processed. Thus the relations built for the immediately preceding sentence are rated highest. This method is based on the hope – which is mostly justified – that an experienced author will write a text reader-friendly, i.e. respecting that human readers must understand the text and recognize correlations. For this, they depend on the author to give them enough facts to build their own text knowledge base. This is a false hope if the writer is incompetent or has to follow certain writing rules, e.g. for patent texts. In these cases, human readers and NLP may fail to understand the text:
b. by giving those relations that are deeply embedded in the semantic net – starting from the text term – a lower weight than those that are directly connected to the text term. Also, the type of relation should be weighted, e.g. a closer relation like the synonymy relation or the partitive relation should be rated higher than an associative relation.
If the approach described appears feasible, the following steps might be taken to realize it:
- Determine an appropriate text collection, large enough and with a consistent subject area (perhaps patents in the field of automobile construction)
- select an appropriate thesaurus / appropriate thesauri
- adapt the thesaurus to the specific needs of NLP as described above
- find / develop / implement an adequate parser and a representation for the semantic net
- test and improve
Conclusion
These considerations are based on work in NLP between the 70s and early 90s, mainly in connection with the SUSY MT system and projects aiming at the application of SUSY and a derived automatic indexing system to texts from specialized fields like patent texts and industrial standards. No attempt has been made as yet to implement the strategy described. SUSY doesn’t appear to be usable in this respect, being a hardly manageable dinosaur from the times of mainframe computers. A different modern MT system will have to be employed, alternatively it would have to be investigated whether a different approach could do without a syntactic pre-analysis. This cannot be assessed here.