
Virtuelles Handbuch Informationswissenschaft
Exkurs: Informationslinguistik
Klassifikationen und Thesauri und die Verarbeitung natürlicher Sprache
Heinz-Dirk Luckhardt
- Einführung: Thesaurus, Klassifikation, Natürliche Sprache
- Anwendungsmöglichkeiten von Klassifikationen
- Grundsätzliches zu Thesauri und ihrer möglichen Verwendung in der MÜ
- Was können ein- oder mehrsprachige Thesauri leisten?
- Übersicht über die verwendeten Thesaurusrelationen
Einführung
Klassifikationen und Thesauri sind Dokumentationssprachen (Dokumentbeschreibungssprachen), d.h. sie werden benutzt, um Dokumente mit einer inhaltlichen Beschreibung zu versehen, anhand derer man diese Dokumente im Zuge des Information Retrievals wiederfinden kann. Der Bezug zur Verarbeitung natürlicher Sprache ist klar: beide Dokumentationssprachen werden vorwiegend benutzt, um natürlichsprachige Texte zu beschreiben, und Thesauri bestehen darüber hinaus (im Gegensatz zu Klassifikationen) selbst aus natürlichsprachigen Begriffen. Allein schon ihre Erstellung und das Arbeiten mit ihnen ist ein Beispiel für die „Verarbeitung natürlicher Sprache“.
Besonders Thesauri haben aber darüber hinaus einige Eigenschaften, die sie für weitere Anwendungen in anderen natürlichsprachlichen Systemen (automatische Indexierung , maschinelle Übersetzung ) interessant machen, v.a. die Eindeutigkeit von Beziehungen und die Relationierung von Begriffen. Dies ist deswegen interessant, weil es gerade die Mehrdeutigkeit von Wörtern oder größeren linguistischen Einheiten (Wortgruppen, Sätzen/Satzteilen) in natürlichsprachigen Texten ist, die die Verarbeitung natürlichsprachiger Texte so schwierig macht.
Im folgenden zur Illustration zunächst einige willkürlich aus Texten herausgegriffene Mehrdeutigkeiten:
(1) … Randeffekte ausschalten …
(2) … die Bildung von Keimen …
(3) … im Verlauf von Walzen und Wärmebehandlung …
(4) …, während der Kern konvektiv erhitzt wird …
(5) Abwasserabgabe – [sewage charge, sewage discharge]
(6a) Während des Betriebs nicht rauchen.
(6b) Nicht rauchen, während das Gerät läuft.
(7)
Singular Plural
________________________________
/--- Vortrag ----- Vorträge
paper /--- Aufsatz ----- Aufsätze
--- Papier ----- -
--- - ----- Ausweispapiere
Mehrdeutigkeiten (vgl. die in den Beispielen kursiv gedruckten Wörter) können auf die verschiedensten Arten angegangen werden (vgl. Luckhardt 1987). Die einfachsten Kriterien sind morphologische, wie in (7). Hier kann mit dem Attribut „Numerus“ jeweils eine der vier Lesarten eliminiert werden: ‚paper‘ im Singular schließt die Lesart ‚Ausweispapiere‘ aus und ‚paper‘ im Plural schließt die Lesart ‚Papier‘ aus. Die syntaktische Analyse wird in der Regel Mehrdeutigkeiten wie in (6) lösen, d.h. die Anwendung der Grammatikregeln sollte automatisch dazu führen, daß „während“ in (6a) als Präposition und in (6b) als Konjunktion erkannt wird. Semanto-syntaktische Kriterien können in Fällen wie (1) greifen, in denen z.B. die semantische Kategorie bestimmter Verbargumente eine Rolle spielt. Damit „ausschalten“ durch „switch off“ übersetzt werden kann, sollte ein evtl. vorhandenes direktes Objekt konkret sein. Bei einem abstrakten Objekt ist eher „eliminate“ angebracht.
All diese Kriterien fallen in den Bereich der linguistischen Analyse, die auf Wort-, Satz- und Textebene die linguistischen Strukturen ermittelt, sie in einer geeigneten Repräsentation festhält und auf dieser Grundlage Mehrdeutigkeiten eliminiert. Diese Analyse stößt früher oder später an Grenzen, jenseits derer man Wissen über den in dem Text behandelten Weltausschnitt benötigt. Die Grenzen sind dabei fließend, wie man an Beispielen wie (2) oder (3) sehen kann. „Keime“ können natürlich keine (Universitäts-)Bildung haben, das weiß der menschliche Leser dieses Textes sofort. Der Computer erzeugt – bestenfalls – zunächst zwei linguistische Analyseergebnisse: eines, bei dem „Keim“ Objekt eines zugrundeliegenden Handlungsverbs „bilden“ ist, und ein weiteres, bei dem „Keim“ Träger einer Eigenschaft „Bildung“ ist. An dieser Stelle ist nun eine Kompatibilitätsprüfung gefordert, die die ermittelten linguistischen Strukturen aufgrund des Wissens über die Welt des Textes verifiziert oder verwirft, hier also über Wissen darüber verfügt, wer oder was bzw. wer oder was nicht über „Bildung“ verfügen kann. Wohlgemerkt, ohne die linguistischen Strukturen geht es nicht, denn sie stellen Beziehungen zwischen den Konzepten her, ohne die diese Konzepte nur eine reine Liste darstellen würden.
Ähnlich die Mehrdeutigkeit in (3): „Walzen“ wird dem menschlichen Leser vielleicht gar nicht mehrdeutig vorkommen, der Computer aber wird je eine Lesart mit dem Objekt „Walze“ (Plural) und mit der Handlung „Walzen“ produzieren. Die erste, linguistisch sinnvolle Lesart kann wiederum nur mithilfe irgendwie gearteten Domänenwissens eliminiert werden.
Soweit einige Beispiele für die Notwendigkeit von Wissen über den zu bearbeitenden Text und seinen Kontext, in welcher Form das Wissen auch immer vorliegt. Wir kommen jetzt zu der Frage, inwieweit Klassifikationen oder Thesauri als Wissensrepräsentationsformen für diesen Zweck geeignet sind.
Anwendungsmöglichkeiten von Klassifikationen
Als Beispiel für eine Klassifikation wurde die Internationale Patentklassifikation (IPC) ausgewählt, weil damit in Saarbrücken in verschiedenen Projekten im Zusammenhang mit computergestützter Terminologiearbeit bereits einige Erfahrungen gewonnen wurden (vgl. Luckhardt/Zimmermann 1991) und weil es ein sehr großes Reservoir an Texten gibt, die nach der IPC klassiert sind.
Wir wollen einen Schnitt durch die IPC machen, der alle Untergliederungen umfaßt, also bis auf die Untergruppen-Ebene hinuntergeht. Die unterste Ebene in unserer Darstellung bilden zwei Untergruppen, die in der englischen IPC beide die Benennung ‚pin‘ enthalten, die jeweils für verschiedene Begriffe stehen (vgl. ABB. 1).
Ideal schiene auf den ersten Blick das folgende Szenario: Ein zu übersetzender/zu indexierender Text sei nach der gleichen feinen Klassifizierung klassiert wie die Einträge des verwendeten Computerlexikons. Somit wäre das englische Wort „pin“ eindeutig mit „Sperrstift“ oder „Kegel“ zu übersetzen bzw. könnte bei einer multilingualen Indexierung „Sperrstift“ oder „Kegel“ zugeordnet werden, je nachdem, ob der Text einer der Untergruppen A63B 29/.. oder A63D 1/.. zuzuordnen ist.

Dieser „Idealfall“ ist in mehrfacher Hinsicht überhaupt nicht „ideal“:
- So ließen sich allenfalls Patente übersetzen, da nur Patenttexte so klassiert und klassierbar sind, zumal die IPC nur patentrelevante Sachen und Sachverhalte umfaßt, nicht aber z.B. Abstrakta. Das wäre noch kein hinreichendes ausschließendes Kriterium, denn der Bedarf an Patentübersetzungen ist enorm, und ein MÜ- oder Indexierungs-System nur für Patente würde sich sicher rentieren.
- Selbst für diese Anwendung ist nicht immer eine eindeutige Klassenzuordnung (auf Haupt- und Untergruppenebene) zu einem Text möglich. Patenten werden meist mehrere Klassen zugeordnet, was sich dadurch ausdrückt, daß pro Patent eine IPC-Hauptklasse und meist mehrere Nebenklassen vergeben werden.
- Selbst wenn man 1. und 2. in Kauf nimmt, ergibt sich immer noch das Problem der Zuordnung der Äquivalente im Lexikon nach den feinen Klassen, eine Arbeit, die intellektuell nicht zu bewältigen ist, die allenfalls durch (halb-)automatische Verfahren erledigt werden kann, also durch Vergleichsverfahren zwischen den elektronischen Versionen der deutschen und der englischen IPC.
- Was würde das Ergebnis eines solchen Verfahrens sein? Ein gewaltig aufgeblähtes Lexikon, da zahlreiche (mehrdeutige) Begriffe in Hunderten von Hauptgruppen vorkommen und – wenn man die feinste Klassifizierung beibehalten wollte – für jede dieser Hauptgruppen je einmal ins Lexikon eingetragen werden müßten. Ein solches automatisch aufgebautes Lexikon wird für die intellektuelle Wartung vermutlich zu groß. Der dafür erforderliche Aufwand wäre nicht zu finanzieren.
- Das Lexikon wird bei einem solchen Verfahren auch dadurch aufgebläht, daß, z.B. innerhalb der englischen Fassung der IPC, Konzepte nicht einheitlich benannt werden, daß z.B. „Ballenpresse“ an einer Stelle „baler“ und an einer anderen „baling press“ heißt. Hier wäre tatsächlich ein Thesaurus angebracht.
Zu fein sollen die Klassen auch deshalb nicht sein, weil es – selbst noch auf der Ebene der IPC-Klassen – zu viele Zuordnungsprobleme (zu der einen oder anderen Klasse), also zu viele Überschneidungen gibt. „Backöfen“ werden z.B. in vier verschiedenen Klassen behandelt.
Die Konsequenz dieser Argumente ist, daß man versucht, von den ganz feinen Klassen zu abstrahieren, ohne zu viel von ihrem Differenzierungspotential zu verlieren. Wenn man nämlich grobe Klassen wählt, fallen zu viele verschiedene Äquivalente in die gleiche Klasse und können nicht mehr differenziert werden.
Eine Klassifizierung auf der Grundlage der IPC, die in der maschinellen Übersetzung einsetzbar sein könnte, scheint etwa zwischen den Klassen und den Untersektionen zu liegen, also auf einer Ebene, die auch für Maschinelle Übersetzungssysteme wie SYSTRAN oder SUSY gewählt wurde, die also etwa Klassen wie die folgenden enthalten könnte:
- …
- Landwirtschaft
- Nahrungsmittel und Tabak
- Persönlicher Bedarf
- Gesundheitswesen
- Sport und Spiel
- …
Grundsätzliches zu Thesauri und ihrer möglichen Verwendung in der MÜ
Über die Verwendbarkeit von Thesauri in der maschinellen Sprachverarbeitung ist noch wenig bekannt. Auch wird der Begriff „Thesaurus“ nicht einheitlich interpretiert. Morris / Hirst verwenden, z.B., für ihren Ansatz zur Ermittlung von „lexical chains“ in Texten den Thesaurusbegriff so, wie er in Rogets Thesaurus benutzt wird: „The thesaurus simply groups words by idea. It does not have to name or classify the idea or relationship“ (Morris / Hirst 1991, 28). Ob dieser rein assoziative Ansatz für die MÜ brauchbar ist, wird weiter unten diskutiert. An dieser Stelle ist eine kurze Erläuterung der Ergebnisse der Untersuchungen von Morris / Hirst angebracht.
„Lexical chains“ verbinden miteinander verwandte Textwörter, die zum Thema eines Textes gehören, und sagen etwas über die Textstruktur aus (letzteres ist das Hauptanliegen von Morris /Hirst). Morris / Hirst benutzen Rogets Thesaurus als Wissensquelle für die Berechnung von lexical chains, die auch den semantischen Kontext für die Interpretation von Wörtern, Konzepten und Sätzen und somit auch für die Vereindeutigung ambiger Wörter bilden können. Für die Bildung der lexical chains wird der Index zu Rogets Thesaurus verwendet, der zu jedem Thesaurusbegriff all die Stellen (Kategorien) aufführt, an denen er vorkommt. Jeder Verweis entspricht also einer Lesart des Wortes. Das Verfahren bestand darin, daß von Hand (eine maschinenlesbare Version des Thesaurus lag nicht vor) die Textwörter, die der gleichen Kategorie zugehörten, zu Ketten zusammengefaßt wurden. Morris / Hirst kamen zu dem folgenden Schluß: „The lexical chains computed by the algorithm given in Section 3.2.3 correspond closely to the intentional structure …“ (vgl. Morris / Hirst 1991, 40).
Lexikalische Ketten fassen nach Morris / Hirst Wörter zusammen, die zu einem Themenbereich gehören („that are about the same topic“), und liefern eine weitere Bestätigung der „lexical cohesion“ von Texten nach Halliday / Hasan (1976). In welcher Weise das Wissen darüber, daß bestimmte Wörter zu einem gemeinsamen Thema gehören, zur automatischen Vereindeutigung dieser Wörter dienen kann, wird weiter unten erörtert werden.
Zunächst wollen wir die Sicht auf den Thesaurusbegriff erweitern, indem wir seine Verwendung im Information Retrieval und den Sinn von Thesaurusrelationen in der MÜ diskutieren, v.a. die Frage: Was macht Thesauri, wie sie in der DIN 1463 beschrieben werden, für ihren Einsatz in der MÜ attraktiv? Schließlich gibt es bereits eine große Anzahl von Thesauri für verschiedene Wissensgebiete, die vielleicht in der MÜ nutzbringend eingesetzt werden könnten. Die folgenden Beispiele entstammen der DIN 1463.
1. Eindeutigkeit von Bezeichnungen
In Thesauri sollen die verwendeten Bezeichnungen eindeutig sein. Dies geschieht durch Verweis von mehrdeutigen Bezeichnungen auf eindeutige:
Eiweiß USE Eiklar
Eiweiß USE Protein
(a USE b = benutze b für a)
oder durch Kennzeichnung von Homonymen/Polysemen:
Kiefer (Knochen)
Kiefer (Nadelholz)
Kiefer (Baum)
Knie (Körperteil)
Knie (Formstück)
Dies sind Notationshilfen, notwendige Voraussetzung für die Zuordnung von Übersetzungsäquivalenten, aber keine Vereindeutigungskriterien. Diese kann man sich eher von dem 2. Aspekt erhoffen.
Zur Abgrenzung der Begriffe Polysemie/Homonymie/Synonymie:
LAUT URSPRUNG BEDEUTUNG BEISPIEL
Homonymie gleich ungleich ungleich "Kiefer/Kiefer"
Polysemie gleich gleich ungleich "Band/Band"
Synonymie ungleich - gleich/ähnlich "Lift/Aufzug"
Zwei Begriffe sind also z.B. homonym, wenn sie gleich lauten, aber verschiedene
Ursprünge und verschiedene Bedeutungen haben.
2. Relationierung von Begriffen
„Grundsätzlich ist es notwendig, in einem Thesaurus die zwischen Begriffen bzw. ihren Bezeichnungen bestehenden Relationen kenntlich zu machen. Auf diese Weise vermitteln die Beziehungen eines Deskriptors zu anderen Bezeichnungen (…) in gewisser Weise eine Definition des Deskriptors, da es seinen Ort im semantischen Gefüge aufzeigt.“
(DIN 1463, 5)
Es werden drei Arten von Relationen genannt:
a) Äquivalenzrelation, die zwei Bezeichnungen mehr oder weniger äquivalent setzt:
SYN, z.B., könnte zwei Bezeichnungen synonym setzen:
Heirat SYN Eheschließung
Recherche SYN Retrieval
b) Hierarchierelation, zu unterscheiden in
Abstraktionsrelation (generische Relation)
NTG = NARROWER TERM (GENERIC)
BTG = BROADER TERM (GENERIC)
Kraftwagen NTG Personenkraftwagen
Lastkraftwagen BTG Kraftwagen
Bestandsrelation (partitive Relation)
NTP = NARROWER TERM (PARTITIVE)
BTP = BROADER TERM (PARTITIVE)
Auto NTP Automotor
Karosserie BTP Auto
c) Assoziationsrelation RT (für RELATED TERM), die auf irgendeine Art verwandte Begriffe miteinander verbindet, zwischen denen keine der beiden anderen Relationen besteht. Hierunter fällt eine Vielzahl von Verwandtschaftsverhältnissen, z.B.:
Relation Determinationsbegriff - Determinans:
Tierernährung RT Tier
Logische Gleichordnung:
Apfel RT Birne
Nebenordnung:
Bayern RT Hessen
Dotter RT Eiklar
Eiklar RT Eischale
Antonymie:
Hitze RT Kälte
Folge-/Nachfolgebeziehungen:
Vater RT Sohn
Affinität:
Buch RT Lesen
Zahlreiche Dokumentsammlungen wurden nach diesen Prinzipien aufbereitet, Thesauri für eine Vielzahl von Fachgebieten und Anwendungen entwickelt. Kann man diese Thesauri auch für die MÜ von Texten aus diesen Fachgebieten verwenden?
Thesauri dienen „in einem Dokumentationsgebiet zum Indexieren, Speichern und Wiederauffinden“ (DIN 1463, 2). Diese Zweckbestimmung führt zu einigen grundsätzlichen Problemen für die Verwendung existierender für Dokumentationszwecke erstellter Thesauri in der MÜ:
1. Ein Thesaurus deckt stets nur einen kleinen Lexikonausschnitt ab, da in ihm nur „relevante“ Begriffe als Deskriptoren (werden zur Informationswiedergewinnung benutzt) und Nichtdeskriptoren (werden nicht zur Informationswiedergewinnung benutzt, verweisen aber immer auf einen an ihrer Stelle zu verwendenden Deskriptor) enthalten sind. Für die MÜ müßte ein Thesaurus alle Wörter enthalten, die zu vereindeutigen sind bzw. zur Vereindeutigung anderer Wörter dienen können.
2. In herkömmlichen Thesauri werden zur Synonymkontrolle Verb und Substantiv bzw. Tätigkeit und Ergebnis oder Tätigkeit und Instrument zu einer Einheit zusammengefaßt, ohne daß die Beziehung zwischen den beiden angegeben ist. Für die Übersetzung aber sind diese undifferenzierten Gleichsetzungen nicht möglich, vgl.:
Wohnen USE Wohnung
Walzen USE Walze
3. Deskriptoren werden oft nicht nach den dahinterstehenden unterschiedlichen Konzepten unterschieden. Z.B. enthält der EUROVOC-Thesaurus der Europäischen Gemeinschaft den Deskriptor „Beize“, obwohl sich dahinter ganz verschiedene Begriffe verbergen (Verwendung mit Metall, Holz, Leder, Textil, Saatgut, Photos oder beim Kochen; Jagdbegriff; Mittel vs. Aktion, vgl. unten).
4. Welchen Sinn haben Thesaurusrelationen, die in erster Linie zur Informationskomprimierung gedacht sind, in der MÜ? Sind sie eventuell als assoziative Relationen zum Aufbau eines assoziativen Netzes zu gebrauchen? Beispiele aus EUROVOC:
Beratungsbüro USE Engineering
Beize USE Schleifmittel
Kleinrechner USE Computer
Kiwi (Frucht) BROADER TERM tropische Frucht
Berufliche Eignung BROADER TERM Arbeitskräfte
Die genannten Relationen können nicht zur Zuordnung von Übersetzungsäquivalenten genutzt, sondern nur eingeschränkt verwendet werden.
5. Manche Thesaurusbegriffe werden wohl nie in Texten auftauchen, weil sie nur eingeführt wurden, um Begriffe zu subsumieren. Der direkte Bezug zwischen Thesaurus und Text ist aber nötig, um eine Verwendung in der maschinellen Sprachverarbeitung möglich zu machen. So kommt, z.B., ein Deskriptor „Beförderung zu Lande und zu Wasser“ wohl nur selten in einem Text vor. Er ist nur deshalb Teil des EUROVOC-Thesaurus, weil er „Beförderungsart“ subspezifizieren soll (dto. für „Leben in der Gesellschaft“ und „Soziale Fragen“). „Transport über Rohr“ dient lediglich als Klammer für „Gasfernleitung“ und „Ölfernleitung“. So gesehen, sollte ein Thesaurus nur die tatsächlich (häufig) in Texten vorkommenden Begriffe enthalten, die entweder vereindeutigt werden müssen oder selbst der Vereindeutigung dienen.
Diese Probleme legen den Schluß nahe, daß für Dokumentationszwecke erstellte (einsprachige) Thesauri nur eingeschränkt für die maschinelle Sprachverarbeitung eingesetzt werden können. Allgemein sind einige offene Fragen zu nennen, die einer eingehenden Diskussion bedürfen:
1. Vererbung von Merkmalen? Können im Thesaurus Merkmale zwischen Einträgen vererbt werden, in dem Sinne, daß die „narrower terms“ von den „broader terms“ alle Merkmale erben, wie man es von Systemen der Wissensrepräsentation der KI kennt? Sicher nicht für die bestehenden Thesauri, wenn sie BROADER TERM (vgl. oben: „Berufliche Eignung“ BROADER TERM „Arbeitskräfte“) als allgemeine Überordnungsbeziehung enthalten. Auf jeden Fall wäre es im Sinne einer weitergehenden semantischen Analyse interessant, über solche Vererbungsmechanismen zu verfügen.
2. Welche Relationen braucht man? Für die Zwecke der MÜ sollte man zwei Arten von Relationen unterscheiden:
a. allgemeine, also solche, mit denen ein semantisches Netz geknüpft wird (das sind also alle);
b. solche, die bei der Zuordnung von Übersetzungsäquivalenten benutzt werden dürfen (z.B. SYN, UEB).
Assoziative Relationen, beispielsweise, sind am Aufbau des semantischen Netzes beteiligt, sie werden aber nicht zwischen Einträgen verwendet, die als Übersetzungsäquivalente voneinander gelten:
Bienenzucht RT Honig
„Bienenzucht“ hat etwas mit „Honig“ zu tun, die beiden Begriffe bzw. deren Übersetzungen können aber in keinem Fall synonym oder quasisynonym verwendet werden. Eine strenger definierte USE-Relation hingegen kann zwischen zwei Einträgen stehen, die demselben Begriff entsprechen, also „synonym“ sind und somit bei der Übersetzungszuordnung eine Rolle spielen, z.B.:
Band USE Fließband
Fließband UEB assembly line
Bekleidung SYN Kleidung
Kleidung UEB clothing
Die USE-Relation wäre hier so etwas wie eine Vereindeutigungsrelation: In einem bestimmten Kontext, der durch den Text- und Sachzusammenhang bestimmt wird, wird einer vagen Benennung eine eindeutige zugeordnet, die für einen eindeutigen Begriff steht, der eine eindeutige Übersetzung hat, die wiederum für die genannte mehrdeutige Benennung verwendet werden darf.
Welche Relationen im einzelnen benutzt werden sollen, ist noch zu diskutieren.
3. Wie ist der Thesaurus technisch organisiert?
Im Prinzip wird der Thesaurus dadurch erstellt, daß jeweils zwei Benennungen mit einer Relation verknüpft werden und die dadurch entstehenden Konstrukte in einer Datenbank gesammelt werden. Zu klären wäre, in welcher Form das dadurch entstehende semantische Netz repräsentiert und genutzt wird.
Was können ein- oder mehrsprachige Thesauri leisten?
Thesauri dienen – wie oben erwähnt – „in einem Dokumentationsgebiet zum Indexieren, Speichern und Wiederauffinden“ (DIN 1463), mehrsprachige Thesauri dienen „der Vereinfachung des Informationsflusses über Sprachbarrieren hinweg“, u.zw. auch eng bezogen auf die Indexierung und das Information Retrieval. Ein mehrsprachiger Thesaurus verzeichnet die Äquivalenzen zwischen den Bezeichnungen der beteiligten Sprachen – Grundvoraussetzung für eine Verwendung im Rahmen eines Übersetzungssystems.
Ein mehrsprachiger Thesaurus ist aber hierfür nicht vonvorneherein geeignet:
1. wenn quellsprachliche Komposita in der Zielsprache durch Kombination mehrerer Benennungen wiedergegeben werden:
solar heating - [chauffage, energie solaire]
2. wenn der Begriffsumfang eines Wortes durch Definitionen oder Erläuterungen (scope notes) eingeschränkt wird, ohne daß geklärt wird, wie es zu dieser Einschränkung kommt; d.h. der Computer kann im Rahmen des Übersetzungsvorgangs mit einer solchen Zuordnung nichts anfangen, wenn sie nicht regelhaft eingeführt wird (dazu vgl. unten):
Ablauf (Abfluß) UEB discharge
Ableiter (Abfluß) UEB discharge
Abfall (Müll) UEB refuse
3. wenn zur Synonymkontrolle Verb und Substantiv bzw. Tätigkeit und Ergebnis oder Tätigkeit und Instrument zu einer Einheit zusammengefaßt werden, ohne daß die Beziehung zwischen den beiden angegeben ist:
Wohnen - Wohnung
Walzen - Walze
4. Im Englischen werden Termini oft nur im Plural verwendet. Das bereitet zusätzliche Schwierigkeiten beim Abgleich von Thesaurusbegriffen und Textwörtern. Grundsätzlich wird mit Grundformen gearbeitet werden müssen.
5. In einem mehrsprachigen Thesaurus gibt es zwischen den Einträgen der verschiedenen Sprachen kaum wirkliche 1:1-Entsprechungen, da sich Lexikon und Terminologien für jede Sprache selbständig entwickeln. Ein Beispiel aus EUROVOC:
USED FOR USED FOR
Beize <-------- Schleifmittel --------> Beizmittel
--------> <--------
USE USE =/
= USE
--------> scouring
abrasive <-------- material
USED FOR
Da gibt es Unstimmigkeiten. Es ist, z.B., nicht ersichtlich, warum „Beize“ bzw. „Beizmittel“ unter „Schleifmittel“ gefaßt wird. Im Englischen gibt es kein Wort, das – ähnlich wie „Beize“ zu „Schleifmittel“ – zu „abrasive“ in Beziehung gesetzt wird. Und was wie eine Parallele aussieht, nämlich „Schleifmittel/Beizmittel“ und „abrasive/scouring material“, ist keine, zumindest kann man „Beizmittel“ in keiner seiner Lesarten mit „scouring material“ übersetzen.
6. Überhaupt kann ein mehrsprachiger Thesaurus in der Form, in der ein solcher meist vorliegt, nur dazu dienen, eindeutige Äquivalenzen (wenn sie denn wirklich eindeutig sind) festzuhalten, und nicht dazu (was eine erstrebenswerte Verbesserung von Computerlexika sein könnte), Mehrdeutigkeiten aufzulösen:
skidding (forwards) - Rutschen
skidding (sideways) - Schleudern
Dies ist nur eine Notation, wie lautet aber die Regel, die „skidding“ vereindeutigt?
skidding (forwards)
skidding <
skidding (sideways)
Oder:
Zug (Beanspruchung) - tension
Zug (Hebezeug) - hoist
Zug (Eisenbahn) - train
Ein solcherart organisierter Thesaurus ist zunächst nur eine andere Form eines Übersetzungslexikons mit bereits eindeutigen Zuordnungen. Wir wollen uns also der Frage zuwenden, wie ein (einsprachiger) Thesaurus zur Vereindeutigung eingesetzt werden könnte?
Prinzipiell sind die „Mehrdeutigkeiten“ und Unschärfen der natürlichen Sprache (Burkart 1990, 166) des zum Aufbau eines Thesaurus gesammelten Wortguts durch terminologische Kontrolle im Thesaurus selbst ausgemerzt, in einem zu übersetzenden Text sind sie aber noch alle vorhanden; wie können also Text und Thesaurus zusammenkommen?
1. Durch Einschränkung des Thesaurus auf einen Geltungsbereich, in dem keine oder nur wenige Mehrdeutigkeiten auftreten (wie realistisch die Verwirklichung dieses Vorhabens auch immer gesehen werden mag).
So könnten mehrdeutigen ausgangssprachlichen Bezeichnungen über Synonymierelation eindeutig zielsprachliche Bezeichnungen zugewiesen werden:
Band BS Magnetband
Magnetband UEB Magnetic tape
oder in einem anderen Thesaurus
Band BS Fließband
Fließband UEB Assembly line
Besser wäre eine direkte Zuordnung
Band - tape bzw. Band - line
da eine Explizierung „Band => magnetic tape“ bzw. „BAND => assembly line“ ohne Berücksichtigung des Kotextes nicht gerechtfertigt ist. Und für diese einfache Zuordnung braucht man natürlich zunächst einmal keinen Thesaurus. Überhaupt braucht man für die Zuordnung von zielsprachlichen Äquivalenten, an der nur ein Paar
quellsprachliches Äquivalent – zielsprachliches Äquivalent
beteiligt ist, noch keinen Thesaurus.
2. Interessant wird der Einsatz eines Thesaurus erst dann, wenn es gelingt, den Weltausschnitt, den ein Thesaurus beschreibt, mit einem zu übersetzenden Text in Beziehung zu setzen.
Mit anderen Worten: einen Textzusammenhang, der von oberflächlichen Ambiguitäten nur so wimmelt, auf dem Raster des zugrundeliegenden Thesaurus so zu klären, daß überflüssige Lesarten durch den Raster fallen und pro Ambiguität im besten Falle die korrekte Lesart übrig bleibt. Das ist der Traum der Computerlinguistik schlechthin, und zu mehr als einem Gedankenspiel wird es in diesem Beitrag noch nicht reichen. Das Gebiet, in dessen Nähe wir uns damit begeben, wird derzeit von der KI, der Psycholinguistik und der Computerlinguistik intensiv behandelt: die Abbildung von Wissensstrukturen in neuronalen Netzen, wie sie als die zugrundeliegende Wissensstruktur im menschlichen Gehirn vermutet wird. Ich möchte die folgende Erörterung auf elementare Sachverhalte beschränken, nämlich auf das Zusammenwirken von Thesaurusrelationen im Zusammenhang mit der Auflösung von Mehrdeutigkeiten bei der maschinellen und computergestützen Übersetzung und Indexierung.
Man kann sich für unseren Zweck die der MÜ zugrundeliegende Wissensbasis als System von Thesauri – je einer pro Sachgebiet – vorstellen, wobei pro bearbeiteten Text ein Thesaurus oder mehrere nach ihrer Relevanz gewichtete Thesauri aktiviert werden, möglichst anhand eines dem Text mitgegebenen Sachgebietscodes. Wir wollen als Beispiel die Übersetzung von „Band“ zugrundelegen (vgl. (8)).
(8)
Isolierband - tape
Tonband - tape
Zielband - tape
Armband - bracelet
(Leder-)band - strap
(Schuh-)band - lace
(Farb-)band - ribbon
(Faß-)band - hoop
(Säge-)band - band
(Förder-)band - belt
(Fließ-)band - line
Band (Architektur) - bond
Band (Metallver.) - strip
Band (Anatomie) - ligament
Band (Radio) - band
Band (Buch) - volume
Bände - volumes
Es läßt sich in kaum einem Fall eindeutig eine Übersetzung zuordnen, wie z.B.:
Textil ribbon
Sport tape
Schmuck bracelet
Computer [ribbon,tape]
Automobilbau [tape,strip,line]
Nehmen wir an, im Automobilbau-Thesaurus träte „Band“ dreimal auf:
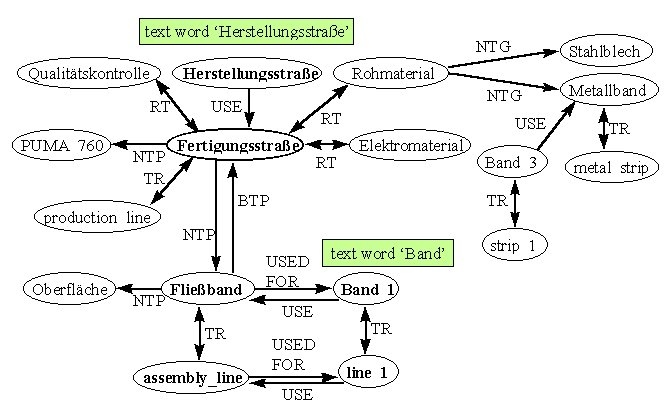
Band USE Isolierband
Band USE Metallband
Band USE Fließband
Weitere Relationen seien die folgenden:
Elektromaterial HAS INSTANCE Isolierband
Elektromaterial HAS INSTANCE Kabel
Rohmaterial HAS INSTANCE Metallband
Fertigungsstraße EQUALS Herstellungsstraße
Fertigungsstraße HAS PART Fließband
Nun sei der folgende Text gegeben:
„Diese Qualitätskontrolle liefert die Ergebnisse rascher und mit höherer Aussagefähigkeit, so daß auch schnellere Rückkopplung und damit Verbesserungen an der Herstellungsstraße möglich sind. Zum Abtasten der Oberflächen werden Laserstrahlen benutzt, da dieses System weniger empfindlich gegenüber ungenauer Positionierung ist. Da die Überwachung am laufenden Band erfolgen muß, wurde der speziell dafür konzipierte Puma 760 ausgewählt. Am Band wird zunächst der jeweilige Autotyp identifiziert …“
Während der Analyse des Textes wird – ausgehend vom zugrundeliegen Thesaurus – eine Textwissenstruktur aufgebaut, in der die gleichzeitig im Text und im Thesaurus enthaltenen Begriffe und ihre semantischen Relationen verzeichnet sind, z.B.:
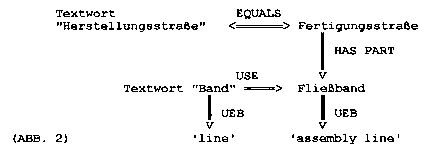
Aus den Thesaurusrelationen läßt sich ein semantisches Netz entwickeln, in dem „Herstellungsstraße“ und „Band“ miteinander in Beziehung stehen, u.zw. „Band“=“Fließband“ und nicht =“Tonband“ oder =“Meßband“. Die Lesart „Fließband“ für „Band“ wird durch „Herstellungsstraße“ aktiviert, und damit die eindeutige Übersetzung „(assembly) line“.
(Abb. 3)
In Abb. 3 ist die Teilstruktur von Abb. 2 in einem grösseren Zusammenhang dargestellt. Das Textwort „Herstellungsstrasse“ soll über die Synonymierelation USE und die Hierarchierelation NTP die fett herausgehobene Teilstruktur „aktivieren“, zu der dann auch „Fliessband“ und damit die korrekte Lesart von „Band“ gehört. Die Teilstrukturen, die die anderen Lesarten von „Band“ enthalten, sind nicht aktiviert, weil sie über „schwächere“ Assoziationsrelationen (RT) zu erreichen und tiefer in die Struktur eingebettet sind, also „weiter weg“ sind vom auslösenden Knoten.
Diese Überlegungen werfen zahlreiche Fragen auf, auf die wohl erst eine erfolgreiche Implementierung Antworten finden kann:
1. Es sind ja nicht nur die Begriffe des Fachgebiets „Automobilbau“ mehrdeutig, sondern auch die allgemeinsprachlichen oder die anderer Fachgebiete („empfindlich“, „Überwachung“, „am laufenden Band“, „Abtasten“). Das Zusammenspiel mehrerer Thesauri muß also geklärt werden, ebenso die Abgrenzung von Thesauri, die für einen Text nicht aktiviert werden sollen.
2. Ebenso muß das Zusammenwirken verschiedener Disambiguierungsmethoden festgelegt werden. Grundsätzlich wird es wohl so sein, daß Thesauri dann eingesetzt werden, wenn syntakto-semantische Kriterien die gröbsten Ambiguitäten weggeräumt haben, da diese in der Regel sicherer greifen.
3. Größtes Problem wird wohl sein, daß zu viele und zu vage Relationen für einen Text(-ausschnitt) aufgebaut werden. Wie kann man sicherstellen, daß möglichst viele relevante und möglichst wenige bedeutungslose Beziehungen aufgebaut werden? Man kann aufgrund verschiedener Kriterien zu einer Gewichtung von Relationen bzw. von Wegen im aufgebauten semantischen Netz kommen:
a. indem man Relationen „altern“ läßt, d.h. das Gewicht von Relationen, die in weiter zurückliegenden Sätzen des Textes aufgebaut wurden, verringert. So werden die Relationen aus dem unmittelbar vorangehenden Satz, also der „frischeste“ Bezug, am höchsten bewertet. Dies Vorgehen gründet auf der meist begründeten Hoffnung, daß ein erfahrener Autor seinen Text lesergerecht schreibt, also unter Berücksichtigung der Tatsache, daß ja auch der menschliche Leser den Text verstehen, Zusammenhänge erkennen soll. Diese Hoffnung trügt dann, wenn ein Schreiber mit dem Abfassen eines Textes überfordert oder an bestimmte Gesetzmäßigkeiten gebunden ist, wie es bei Patenttexten oft der Fall ist;
b. indem man Relationen, die – ausgehend vom auslösenden Textbegriff – tief in das semantische Netz eingebettet sind, niedriger gewichtet als z.B. solche, die unmittelbar von einem auslösenden Begriff ausgehen. Auch sollte die Art der Relation gewichtet werden, beispielsweise eine „engere“ wie die Synonymierelation oder die Teil-Ganzes-Relation höher als eine vage wie die Assoziationsrelation.
4. Es erhebt sich auch die Frage, welche Auswirkungen Erweiterungen von Thesauri haben, insbesondere auch im Hinblick auf die Gewichtung von Relationen. Dieses Problem kann man in einem ersten Ansatz so angehen, daß Thesauri vonvorneherein möglichst vollständig angelegt werden und im Falle einer doch notwendigen Erweiterung von System Hilfen angeboten werden, die die alte Struktur in die neue überführen, ohne daß das bisherige System von Gewichtungen unbrauchbar wird.
Man sieht, daß dieses Gedankengebäude noch auf unsicheren Fundamenten steht, weil noch nichts davon implementiert ist, und es werden zu den obigen Fragen sicher noch weitere hinzukommen.
Übersicht über die verwendeten Thesaurusrelationen:
USE = BENUTZE (Äquivalenzrelation, Verweis auf Vorzugsbenennung/Deskriptor) USED FOR = BENUTZT FÜR (Äquivalenzrelation, Verweis auf Nichtdeskriptor) BTG = BROADER TERM (GENERIC) (Abstraktionsrelation) BTP = BROADER TERM (PARTITIVE) (Bestandsrelation) NTG = NARROWER TERM (GENERIC) = HAS INSTANCE (Abstraktionsrelation) NTP = NARROWER TERM (PARTIVE) = HAS PART (Bestandsrelation) SYN = EQUALS (Synonymierelation, Äquivalenzrelation) RT (Assoziationsrelation) UEB (Übersetzungsrelation, a und b sind Übersetzungsäquivalente voneinander)