
Identität und Geschichte der Informationswissenschaft
Information und Sprache
Thema:Information und Sprache
Projekte: Identität und Geschichte der Informationswissenschaft
II.II. Methoden und Verfahren der Informationslinguistik
II.II.I. Spracherkennung
a) Definition
„(Maschinelle) Spracherkennung“ (= ASR für engl.: Automatic Speech Recognition) meint die Umwandlung von gesprochener Sprache in Text mittels einer Spracherkennungssoftware. Bei der Spracherkennung unterscheidet man grob drei verschiedene Verfahrensweisen:
1) Ziel der ersten ist es, ein Spracherkennungssystem zu entwickeln, das eine kleine Anzahl von Wörtern versteht, die von einer großen Bandbreite von Menschen verwendet werden. Diese Methode erzielt recht gute Erfolge.
2) Ziel der zweiten ist es, ein Sprachsystem zu entwickeln, das eine große Anzahl von Wörtern erkennt, die eine einzige Person gebraucht. Wenn die Sprachmuster dieser Person eine bestimmte Kontinuität aufweisen, ist auch diese Methode zuverlässig.
3) Ziel der dritten ist es, ein Spracherkennungssystem zu entwickeln, das die Sprachmuster einer bestimmten Person lernt und dieses auf eine große Menge von Wörtern anwenden kann. Diese Methode scheint für eine Sprach-Text-Umwandlung am erfolgversprechendsten, ist jedoch noch am wenigsten zuverlässig (vgl. MS Encarta:1999: Stichwort „Spracherkennung“).
b) Der Prozess der Spracherkennung
Die Texteingabe erfolgt über ein Mikrofon, das mit dem entsprechenden Eingang der Soundkarte verbunden ist. Damit ein Computer die menschliche Sprache, die aus Schallwellen besteht, erfassen kann, müssen diese in ein binäres Signal umgewandelt werden. Dieses binäre Signal muss mit Hilfe einer Spracherkennungssoftware verarbeitet werden, damit für den Computer eine sinnvolle Information entsteht.
Diese Software kann natürlich nur Wörter verarbeiten, die ihr bekannt sind. Aus diesem Grund benötigen Spracherkennungsprogramme Ressourcen in Form von möglichst großen Begriffsdatenbanken (Um das ganze mit Zahlen zu veranschaulichen: Basissysteme besitzen eine Datenbank von durchschnittlich 30.000 Begriffen, Profisysteme können auf 60.000 Stichworte zurückgreifen). Die eingegebenen Wörter werden mittels hochentwickelter mathematischer Algorithmen mit den Einträgen in der Datenbank verglichen und entsprechend umgesetzt. Hauptschwierigkeit besteht dabei darin, aus einer kontinuierlichen Kette binärer Signale natürlichsprachige Wörter zu erzeugen. Man bedient sich dafür physikalischer Methoden: Sprachsignale sind messbar „als kontinuierliche Veränderungen von wahrnehmbaren Lauteigenschaften in der Zeit“ (Gibbon:1997:Sprachsymbole und Sprachsynthese). Das Sprachsignal ist also „eine Folge von Signal-Amplitudenwerten über der Zeitachse. Alle zehn Millisekunden extrahiert der Erkenner aus einem kurzen Abschnitt des digitalisierten Sprachsignals mehrere Merkmale und faßt sie zu einem Vektor zusammen, anhand dessen sich die einzelnen Laute der Sprache identifizieren lassen. Die zeitliche Folge von Merkmalsvektoren bildet die Grundlage für die Entscheidung, welche Wortfolge gesprochen worden ist. Der Spracherkenner ermittelt mit Methoden der Statistik, welcher Satz zu einer Folge von Merkmalsvektoren am besten passt. Dabei benutzt er zwei Wissensquellen:
– Die akustische Wahrscheinlichkeit (eine bedingte Wahrscheinlichkeit) liefert für irgendeine hypothetische Wortfolge die Wahrscheinlichkeit der tatsächlich beobachteten Merkmalsvektoren
– Die linguistische Wahrscheinlichkeit (eine A-priori-Wahrscheinlichkeit) spezifiziert die Wahrscheinlichkeit aller möglichen Wortfolgen. Sie ist unabhängig von den akustischen Daten und nimmt nur Bezug auf die geschriebene Transkription der gesprochenen Sprache (das sogenannte Sprachmodell)“ (Berger:1998:Wie funktioniert automatische Spracherkennung?).
c) Probleme bei der Spracherkennung
– Die Aussprache eines Lautes kann sehr unterschiedlich realisiert werden, sogar dann, wenn es sich um denselben Sprecher handelt.
– Man redet nicht immer mit derselben Sprechgeschwindigkeit
– Wie ein Laut ausgesprochen wird, hängt oft von den jeweils vorausgegangenen Lauten ab (Koartikulation).
– Gesprochene Sprachen trennen nicht nach Worten. Sprache ist eine lineare Kette, ein fortlaufendes Band, in dem das Ohr keine hinlängliche und feststehende Einteilung vernimmt. Die Interpunktion wird in der gesprochenen Sprache ersetzt durch Betonung und Phrasierung.
– In der praktischen Anwendung muss man mit Störfaktoren rechnen, wie z.B. Verkehrslärm.
– Je nach Sprecher kann die Betonung stark variieren.
– Verschiedene Sprecher verwenden verschiedene Dialekte.

II.II.II. Sprachsynthese (-generierung)
Unter „Sprachsynthese“ versteht man „die Erzeugung gesprochener Sprache durch Computer“ (T-Rex). Hauptziel der Forschung auf dem Gebiet der Sprachsynthese ist eine möglichst natürlich klingende Aussprache. Die vom Computer erzeugten Aussagen sollen nicht roboterhaft wirken, ferner muss die Satzmelodie zum jeweiligen Thema passen. Außerdem wird mittels neuronaler Netze versucht, den Stimmcharakter des jeweiligen Sprechers nachzubilden: Es würde nämlich komisch anmuten, wenn eine hohe, weibliche Fistelstimme bei der späteren Sprachausgabe als tiefer, männlicher Bariton ausgegeben würde.
II.II.III. Sprachanalyse
Unter Sprachanalyse versteht man die „Analyse natürlicher (geschriebener oder gesprochener) Sprache durch Computer, v.a. mit den Teilbereichen morphologische (wortbezogen), syntaktische (satzteilbezogen), semantische (bedeutungsbezogen) Analyse, aber auch pragmatische Analyse (Analyse von Sprechakten) und Textanalyse (satzübergreifende Bezüge)“ (T-Rex).
a) Parsing
Das Wort „Parsing“ stammt vom englischen Verb „to parse“, was soviel bedeutet wie: „grammatisch zerlegen“. Beim Parsing geht es allgemein darum, menschliche Aussagen maschinell zu analysieren. Dies geschieht mit Hilfe von spezieller Software (Parser). Das Parsing ist die erste Stufe bei der maschinellen Übersetzung oder bzw. bei linguistischen Verfahren der Indexierung (vgl. T-Rex). Der Prozess des Parsings lässt sich in mehrere Analyse-Schritte unterteilen. Es sind:
1) die automatische Spracherkennung (ASR) (s. Punkt II.II.I.?)
2) die morphologische Analyse
Die morphologische Analyse befasst sich mit der Struktur der Wörter. Sie beschäftigt sich insbesondere mit der Wortbildung, untersucht und beschreibt Form, Vorkommen und Funktion von Morphemen (Morpheme sind kleinste bedeutungstragende Einheiten der Sprache, bspw. „Hof“, „steh-“ oder „Bahn“). Die morphologische Analyse lässt sich ihrerseits wieder untergliedern in Flexions-, Derivations- und Kompositionsanalyse. Die Flexionsanalyse beschäftigt sich mit Wortformen, die im Rahmen von Konjugation, Deklination, Steigerung entstehen (Bsp.:liegen-liegst-liegt). Die Derivationsanalyse untersucht die Struktur von Derivaten, d.h. von Wörtern, die durch Vorstellen eines Präfixes bzw. durch Anhängen eines Suffixes vor bzw. an ein lexikalisches Grundmorphem (Stamm) entstanden sind. (Bsp.: be- (Präfix) + arbeiten (Stamm)→ bearbeiten). Beim Derivationsprozess werden keine Wortformen gebildet. Es entstehen entweder neue Wörter anderer Wortarten (Bsp.: gesund (Adj.) + -heit (Suffix)→ Gesundheit (Subst.)), oder bereits existierende Wörter werden semantisch verändert (Bsp.: un- + fruchtbar → unfruchtbar (Negation). Die Kompositionsanalyse seziert hingegen die Struktur von Komposita (Wortzusammensetzungen). Bei den Komposita unterscheidet man Determinativ- und Kopulativkomposita. Ein Determinativkompositum setzt sich zusammen aus einem Grundwort und einem Bestimmungswort. Das Grundwort dominiert das Bestimmungswort, es legt Wortart sowie grammatische Eigenschaften der Konstruktion fest. Das Bestimmungwort erläutert lediglich das Grundwort in semantischer Hinsicht näher. (Bsp.: Bier + Fass → Bierfass). Bei einem Kopulativkompositum sind die einzelnen Bestandteile (Konstituenten) grammatisch und semantisch gleichberechtigt. Sie entstammen der gleichen Wortart sowie der gleichen Bezeichnungsklasse (Bsp.: Schnee (Subst., Wettererscheinung) + Regen (Subst., Wettererscheinung) → Schneeregen (Subst., Wettererscheinung)). Die morphologische Analyse spielt bei der automatischen Indexierung und Übersetzung eine entscheidende Rolle, da sie die Voraussetzung für eine spätere Zuordnung von im Text vorkommenden Wortformen zu ihrer Grundform bildet. Moderne Parser können Wörter in ihre Einzelteile zerlegen (Deflexion, Dekomposition, Derivation).
| Höf | lich | keit | en |
|---|---|---|---|
| Lex. Grundmorphem | Suffix | Suffix | Flektionsmorphem |
Mit morphologischen Verfahren lassen sich auch automatisch ganze Wortfamilien automatisch zusammenstellen:
Bsp.: realisier- en, -ung, -bar, -barkeit, …
3) die syntaktische Analyse
Die syntaktische Analyse befasst sich mit der Struktur von Wortgruppen, Teilsätzen und ganzen Sätzen. Es wird maschinell überprüft, „ob eine bestimmte Wortkette (z.B. ein Satz) den Regeln einer bestimmten (formalen oder natürlichen) Sprache entspricht. Trifft dies zu, so wird zu der Wortkette eine Repräsentation ihrer syntaktischen (und/ oder semantischen) Struktur (z.B als Phrasenstrukturbaum) erstellt“ (Bußmann:1990:Lexikon der Sprachwissenschaft). Diese Repräsentation gibt Aufschlüsse über die einzelnen linguistischen Bausteine (z.B. Satzglieder), ihre Struktur und ihre Beziehungen zueinander. Sie stellt die Voraussetzung für die Ermittlung sogenannter Mehrwortdeskriptoren dar. Die Bezüge der Einzelglieder zueinander kann beispielsweise eine Dependenzanalyse bzw. Valenzanalyse ermitteln. Die von dem französischen Sprachforscher Lucien Tesnière eingeführte Valenzgrammatik hat ihren Namen aus der Chemie entlehnt. Die chemische Valenz bezeichnet die Fähigkeit von Atomen, „Wasserstoff-Atome einer bestimmten Anzahl im Molekül zu binden bzw. zu ersetzen“ (Bußmann:1990:Lexikon der Sprachwissenschaft). Man versteht unter „Valenz“ „die Fähigkeit eines Lexems (z.B. eines Verbs, Adjektivs, Substantivs), seine syntaktische Umgebung vorzustrukturieren, indem es anderen Konstituenten im Satz Bedingungen bezüglich ihrer grammatischen Eigenschaften auferlegt“ (ebd.). So erzwingt beispielsweise das Verb „essen“ ein Akkusativ-Objekt, das Verb „glauben“ ein Dativ-Objekt. Das Verb wird quasi als Atomkern des Satzes angesehen. Es legt die ihm folgenden Valenzen (Leerstellen) fest, die belegt werden können. Ein monovalentes Verb ist beispielsweise „schlafen“, es zieht kein Objekt nach sich. Ein bivalentes Verb ist „essen“, es zieht ein Objekt (Akk.) nach sich. Ein trivalentes Verb ist beispielweise „jemandem etwas schenken“, es zieht zwei Objekte (Dat., Akk.) nach sich. Parser, die mit syntaktischen Analyse-Verfahren arbeiten, können somit überprüfen, welchen Verben welche Objekte grammatisch zugeordnet werden können und welche nicht. Dabei wird allerdings nur die grammatische Realisierbarkeit überprüft, nicht aber die semantische.
4) die semantische Analyse
Die Überprüfung der semantischen Realisierbarkeit ist Aufgabe der semantischen Analyse. Die semantische Analyse seziert und beschreibt die Bedeutung von sprachlichen Ausdrücken. Ihr Ziel ist es, zu ermitteln, ob eine Aussage „Sinn“ macht. Der Satz „die Maus zertritt den Elefanten“ muss von einem semantischen Analyseverfahren als inkorrekt erkannt werden. Die Semantik untergliedert sich in Wortsemantik, Satzsemantik und Textsemantik. Die Wortsemantik beschäftigt sich mit der Bedeutung von Einzelwörtern, während die Aufgabe der Satz– und der Textsemantik darin besteht, die semantische Relation zwischen den Einzelelementen eines Satzes oder ganzer Texte zu analysieren. Problem bei der semantischen Analyse ist, dass ein und derselbe Sachverhalt je nach Situation unterschiedlich ausgedrückt werden kann. Die semantische Analyse löst dieses Problem, indem sie den Wörtern einer Proposition nicht nur Deskriptoren zuschreibt, sondern auch sogenannte Rollenindikatoren, die es ermöglichen, die verschiedenen Varianten auf eine einzige Repräsentation zu reduzieren.
Ein Beispiel:
Die Formulierung eines Sachverhaltes wird in folgenden Varianten ausgedrückt:
Spürhunde finden Lawinenopfer.
Lawinenopfer werden von Spürhunden gefunden.
Spürhunde können Lawinenopfer finden.
| Rollenindikator | Deskriptoren |
| Subjekt (Handelnder) | Spürhund |
| Handlung | finden |
| Objekt | Lawinenopfer |
5) Pragmatische Analyse
Die Bedeutung einer Äußerung geht jedoch nicht ausschließlich aus der Bedeutung der Wörter, Wortgruppen, Sätze oder Texte hervor. Um eine Aussage richtig aufzufassen, benötigt man oft mehr, als das in der Aussage ausgedrückte Wissen. Man benötigt Wissen über die Sprechsituation, den / die Sprechenden, deren Gestik, Mimik, soziale Normen, und darüberhinaus Wissen, dass man als „allgemeines Weltwissen“ bezeichnen kann (Wenn z.B. in einem Zeitungsartikel die Rede vom 11. September ist, braucht der Journalist dem Leser nicht mehr explizit zu erklären, dass an diesem Tag die Terroranschläge auf das World Trade Center stattgefunden haben). Dieses Wissen wird in der pragmatischen Analyse verwendet.
6) Textanalyse
Die Textanalyse beschäftigt sich mit Beziehungen, die über die Satzebene hinausgehen. Sie analysiert die Faktoren, die einen Text zum Text machen., beschäftigt sich mit Kohäsion und Kohärenz. Der Begriff „Kohäsion“ bezeichnet den durch „formale Mittel der Grammatik hergestellten Textzusammenhang“ (Bußmann:1990:Lexikon der Sprachwissenschaft). Beispielsweise die Tatsache, dass man einen Referenten mit dem unbestimmten Artikel einführt (ein kleiner Hund…), ihn dann im weiteren Verlauf des Textes mit dem bestimmten Artikel kennzeichnet (der kleine Hund…). „Kohärenz“ bezeichnet den „semantischen, der Kohäsion zugrundeliegenden Sinnzusammenhang eines Textes, seine inhaltlich-semantische bzw. kognitive Strukturiertheit“ (ebd.). Je mehr Analyse-Verfahren für einen automatischen Analyse-Prozess eingesetzt werden, desto höher ist die Wahrscheinlichkeit, dass semantische Mehrdeutigkeiten (bspw. Homonymie) aufgelöst werden. Die aus den verschiedenen Analyse-Prozessen gewonnenen Informationen dienen dazu, ein Sprachmodell zu entwickeln. Dieses Sprachmodell soll die linguistische Wahrscheinlichkeit einer Satzhypothese berechnen. Das heißt, bei einem automatischen Analyseprozess soll der Parser dem Satz: „Heute ist schönes Wetter“ eine höhere linguistische Wahrscheinlichkeit zuschreiben als „Der Mutter schläft den Rot“.
b) Tagging
Tagging ist die „Auszeichnung von Wörtern eines laufenden Textes mit ihren grammatischen Informationen, v.a. der Wortklasse“ (T-Rex). Man ordnet also jedem Wort eine exakte grammatische Beschreibung zu. Diese Aufgabe wurde früher ausschließlich von Menschen übernommen, heute lässt man sie von automatischen Parsern erledigen. (s. Punkt II.II.III. a) ?).
II.II.IV. Indexierung (Lemmatisierung)
Unter Indexierung versteht man ein Verfahren, das die Beschreibung von Textdokumenten mittels sogenannter Deskriptoren zum Ziel hat. Es geht darum, Wissenseinheiten aus Texten natürlichsprachlich zu beschreiben, damit die User bei der späteren Recherche keine komplizierten Zahlen- oder Buchstabencodes benutzen müssen, sondern ihre Suchanfragen mit Hilfe natürlichsprachiger Ausdrücke formulieren können. Deskriptoren sind inhaltsbeschreibende Begriffe. Entstammen sie dem Text (Stichwörter), werden sie beim Prozess der Indexierung durch Extraktion gewonnen (Extraktionsmethode). Kommen sie nicht wörtlich im Text vor, werden sie im Nachhinein von Indexierern, die über eine hohe Kenntnis des Fachgebiets verfügen, vergeben (Additionsmethode). Alle Deskriptoren zusammen bilden den Index der Datenbank.
Hauptziel der Indexierung ist es zu ermöglichen, dass der User im Zuge der Informationsrecherche (Information Retrieval) auf möglichst vielen Wege zu den Dokumenten gelangen kann, die für seine spezifischen Vorstellungen von Bedeutung sind.
Grafik entnommen aus: Die Deutsche Bibliothek:2001: Wissenswertes zur Indexierung
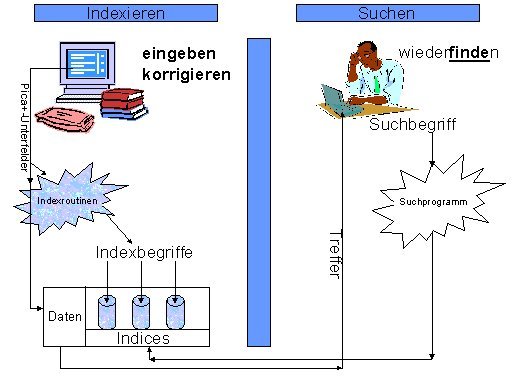
Man unterscheidet drei verschiedene Formen von Indexierung:
a) intellektuelle Indexierung
Von intellektueller Indexierung spricht man dann, wenn die Deskriptoren von Personen (sogenannten Indexierern) vergeben werden.
b) computergestützte Indexierung
Von computergestützter Indexierung reden wir, wenn sowohl Mensch als auch Maschine am Indexierungsprozess beteiligt sind. Das ist zum Beispiel dann der Fall, wenn der Computer eine Reihe von Deskriptoren vorschlägt und ein Indexierer aus dieser Menge diejenigen auswählt, die ihm am geeignetsten erscheinen.
c) automatische Indexierung
Bei der automatischen (oder auch maschinellen) Indexierung wird der Indexierungsprozess ausschließlich von Computern durchgeführt. Man unterscheidet verschiedene Verfahren. Es sind:
1) das Freitextverfahren (full text indexing)
Beim Freitextverfahren werden alle Wörter eines Textes zur Stichwortextraktion verwendet. Eine Ausnahme bilden nur die „Stoppwörter„. Das sind inhaltsleere Wörter, wie z.B. Pronomen, Konjunktionen, Hilfsverben oder Wörter, die auf bestimmten Fachgebieten so häufig sind, dass es keinen Sinn machen würde, sie zu indexieren (Wie z.B. „Software“ oder „Rechner“ im Fachbereich Informatik). Vorteil des Freitextverfahrens ist, dass es sehr rasch vonstatten geht und ohne menschliche Arbeitskräfte auskommt. Nachteil ist, dass es ohne intellektuelle Kontrolle auskommen muss und somit Fehler vorprogrammiert sind. Aus diesem Grund bezeichnet man das Freitextverfahren auch als „quick and dirty„, als schnell aber von schlechter Qualität. Auch bei der späteren Recherche ergeben sich Nachteile. Suchen kann man nur mit den exakten Wortformen, höchstens noch mit trunkierten Varianten. Sobald die Begriffe jedoch in einer anderen grammatischen Form auftauchen, werden sie nicht mehr aufgespürt.
2) Morphologisch-lexikalische, morphologisch-syntaktische, semantische Verfahren
Bei diesen Verfahren werden die Wortformen zunächst analysiert und erst im Anschluss daran indexiert. Die Verfahren entsprechen denen der Sprachanalyse (s.Punkt II.II.III.?). In einem so entstandenen Index muss man seine Suchbegriffe nicht auf bestimmte grammatische Formen beschränken, man kann sowohl mit diesen suchen als auch mit dem entsprechenden Grundwort. Möglich sind auch Mehrwortdeskriptoren oder komplexere natürlichsprachige Suchanfragen.
Beispiel für ein System, das nach einem morphologisch-syntaktischen Verfahren arbeitet, ist das in den 80er Jahren an der Universität des Saarlandes entwickelte syntaktische Indexierungssystem CTX (Computergestützte Texterschließung). CTX erfüllte folgende Aufgaben:
– Grundwortermittlung
– Dekomposition
– Syntaktische Analyse
– Ermittlung von Mehrwortdeskriptoren
I.II.V. Abstracting
Beim Abstracting erstellt man eine kurze Zusammenfassung eines Textes, ein sogenanntes Abstract oder Referat. Erstellt der Autor eines Textes selbst das Abstract, spricht man von einem Autor-Referat, erstellt eine andere Person die Kurzzusammenfassung, spricht man von einem Fremd-Referat. Weil sich automatische Verfahren als äußerst unzuverlässig erwiesen haben, erstellt man Abstracts derzeit fast nur noch intellektuell. Die Entwicklung verlässlicherer Methoden für automatisches oder computergestütztes Abstracting stellt für die Zukunft eine große Herausforderung für die Computerlinguistik und die künstliche Intelligenz dar.
II.II.VI. Information Extraction
Information Extraction ist ein maschinelles Verfahren, bei dem man strukturierte Wissenseinheiten aus einem Text extrahiert. Es wird u.a. beim Auswerten von Berichten oder beim Recherchieren in einer Datenbank nach speziellen Themen angewandt (vgl. Luckhardt: 2000:Teilbereiche der Informationslinguistik und Verbindungen zu anderen Disziplinen).
II.II.VII. Übersetzung
Im Zeitalter globaler Kommunikation stellen Sprachbarrieren ein großes Hindernis für die internationale Verständigung dar. Überwindung dieser Sprachbarrieren ist das Hauptziel der drei verschiedenen Übersetzungsverfahren.
a) intellektuelle Übersetzung
Bei der intellektuellen Übersetzung sind Menschen als Übersetzer tätig.
b) computergestützte Übersetzung (computer aided translation, kurz: CAT)
Bei der computergestützten Übersetzung erfolgt eine Zusammenarbeit zwischen Mensch und Maschine. Man unterscheidet zwei verschiedene Formen:
1) HAMT (human aided machine translation)
Bei der HAMT übersetzt der Computer den Text grob. Der Mensch vervollkommnet den Text durch Vor- oder Nachbereitung (Prä- oder Postedition) (Vgl. T-Rex).
2) MAHT (machine aided human translation)
Bei der MAHT übersetzt der Mensch. Der Computer leistet ihm Unterstützung, indem er „automatisch entsprechende Fachbegriffe übersetzt (‚automatic dictionary look-up‘) und den Text mit früheren Übersetzungen vergleicht (‚translation memory‚)“ (T-Rex).
Auf dem Gebiet der computergestützten Übersetzung hat in den letzten Jahren eine interessante Entwicklung stattgefunden. Statt sich ausschließlich mit der Verbesserung morphologisch-, syntaktisch-, analytischer Verfahren zu beschäftigen, die trotz fortschrittlicher Ergebnisse immer noch relativ unzuverlässig sind, hat man daneben begonnen, sogenannte Übersetzungsspeicher (translation memories) zu kreieren. Bei diesen handelt es sich um Archive mit bereits übersetzten Paralleltexten (bspw. Versionen von Handbüchern und Bedienungsanleitungen). Wenn ein Satz übersetzt werden soll, der in ähnlicher Form bereits einmal in die entsprechende Sprache übertragen worden ist, braucht dieser nicht erneut analysiert und übersetzt zu werden, sondern man verwendet die bereits vorhandene Übersetzung wieder. Der Vorteil dieser Programme liegt in der Fähigkeit, solche analogen Sätze zu finden. Diese Systeme arbeiten nicht rein maschinell, sondern präsentieren die gefundenen Möglichkeit dem Benutzer, der entscheidet, ob man das Ergebnis so durchgehen lassen kann oder nicht.
c) automatische Übersetzung (maschinelle Übersetzung)
Unter „automatischer Übersetzung“ versteht man die vollautomatische Übersetzung von Texten von einer natürlichen Sprache in eine andere. Übersetzen ist eine der komplexesten sprachlichen Tätigkeiten. Dennoch war die maschinelle Übersetzung (MÜ) eine der frühesten Anwendungen der Computertechnik. Bereits 1949 begann man auf diesem Gebiet mit Forschungen. Zunächst lag die wissenschaftliche Tätigkeit hauptsächlich in den Händen der Amerikaner, die sich, angesichts des Kalten Krieges, auf das Sprachpaar Russisch-Englisch konzentrierten. Da man sich lediglich auf Wort-für-Wort-Übersetzungssysteme beschränkte, waren die Forschungsergebnisse jedoch enttäuschend. 1966 erschien der sogenannte ALPAC-Report. In diesem wurde festgehalten, dass es keine zuverlässige MÜ gebe, dieses Forschungsziel voraussichtlich auch nie erreicht werde. Daraufhin verweigerte der Staat die finanzielle Unterstützung solcher Projekte. Der Forschungsschwerpunkt verlagerte sich nach Europa. Die ersten europäischen Projekte entstanden an den Universitäten Grenoble (GETA/ARIANE) und Saarbrücken (SUSY).
Einige technische Angaben zu SUSY:
– SUSY wurde 1972-1986 vom Sonderforschungsbereich 100 „Elektronische Sprachforschung“ entwickelt
– kam zwischen 1981 und 1990 zum praktischen Einsatz (Fachrichtung Informations- wissenschaft)
– wurde auf Rechnern der folgenden Firmen installiert: Control Data => Telefunken => Siemens => Nixdorf Targon => Solbourne => Silicon Graphics (1998)
– ist seit 1995 online
Das SUSY-System kann online verwendet werden, um vom Deutschen ins Englische und vom Russischen ins Deutsche zu übersetzen (vgl. Universität des Saarlandes:1998:SUSY-Das Saarbrücker Übersetzungssystem, http://www.is.uni-sb.de/projekte/aktuell/natlangs/susytest.html). Um die Ergebnisse zu verbessern, machte man sich die Forschungen der Sprachwissenschaft zunutze, beschränkte sich nicht mehr länger auf die einfache Wort-für-Wort-Übersetzung, sondern entwickelte morphologisch-syntaktisch-semantische Verfahren, die sich mit der satzweisen Übersetzung ganzer Texte mit Analyse von Satzbau und Grammatik befassten, und die sich als zuverlässiger erwiesen. Trotz der errungenen Erfolge ist die maschinelle Übersetzung jedoch noch weit von ihrem eigentlichen Ziel, der FAHQT (fully automatic high-quality translation) entfernt. Grund dafür ist, dass nicht alle Wissenseinheiten eines Textes verbal kodiert sind. Was sich unter den Oberbegriffen „Kontextwissen“ und „Weltwissen“ zusammenfassen lässt, bleibt implizit und kann somit von einer Maschine nicht erschlossen werden. Die Hauptschwierigkeit der neueren Forschung besteht darin, ein System zu entwickeln, wie man diese unausgedrückten Informationen darstellen und organisieren kann, damit einer Übersetzungssoftware stets alle, zumindest aber die für die konkrete Situation relevanten Informationen zur Verfügung stehen. Die Entwicklung tendiert dazu, sich für die Lösung dieser Probleme die Erkenntnisse der Künstlichen Intelligenz und der Kognitionswissenschaft zunutze zu machen. Zudem geht die Entwicklung in Richtung quantitativer Methoden, die, ähnlich wie die Übersetzungsspeicher in der computergestützten Übersetzung, auf der Basis umfangreicher, bereits bestehender Übersetzungen aufbauen.
Nach klassischer Vorgehensweise läuft die maschinelle Übersetzung in drei Stufen ab (nach Bußmann:1990:Lexikon der Sprachwissenschaft):
a) Analyse der Ausgangssprache mittels Parsing
b) Transfer: Übertragung der Ausgangssprache in die Zielsprache
c) Synthese: Generierung der Zielsprache
 zum Inhaltsverzeichnis | II.III Ressourcen der Informationslinguistik
zum Inhaltsverzeichnis | II.III Ressourcen der Informationslinguistik 