
Virtuelles Handbuch Informationswissenschaft
Exkurs: Informationslinguistik
Die Bedeutung von Sprache für die Entwicklung und Nutzung von Informationssystemen
Heinz-Dirk Luckhardt
Sprache und Informationssysteme
Die Bedeutung von Sprache für Informations- und Kommunikationssysteme kann man sehr leicht erschließen, wenn man sich Folgendes bewusst macht (wenn auch manches vielleicht etwas überzeichnet scheint):
- Als erstes eine Klarstellung: Mit „Sprache“ ist im Folgenden (geschriebene und gesprochene) „natürliche Sprache“ gemeint, im Unterschied zu künstlichen Sprachen (wie Programmiersprachen) oder Plansprachen (wie Esperanto).
- Sprache ist das wichtigste, schwierigste und vielseitigste Kommunikationsmittel.
- Sprache ist im Zeitalter der Emails und Newsgruppen insofern eine stark vernachlässigte Größe, als die Beschleunigung der schriftlichen Kommunikation zu einer Verwahrlosung der Sprache und damit zu einer Verschlechterung der Kommunikation führen kann.
- Informationen werden am häufigsten sprachlich übermittelt. Bilder, Graphiken, laufende Bilder etc. sind am wichtigsten als Illustration, als ergänzendes Mittel zur Informationspräsentation.
- Wissen wird durch Sprache übermittelt: durch mündliche Vorträge, durch schriftliche Beiträge in Zeitschriften, Monographien, Sammelbänden, Websites etc. Das meiste in Datenbanken gespeicherte Wissen ist sprachlich kodiert.
- Auch im Mittelpunkt des WWW steht Sprache, alles andere ist nur Garnierung (evtl. abgesehen von reinen Unterhaltungsangeboten).
- Keine Benutzungsschnittstelle kommt ohne Sprache aus. Dabei sind die sprachlichen Mittel von unterschiedlicher Komplexität (Einzelwörter, Wortlisten, Syntagmen, ganze Sätze, Fragesätze, Befehle, …; Probleme: Mehrsprachigkeit, Terminologien, Sublanguages).
- Nichts ist so mehrdeutig wie natürliche Sprache, kaum ein linguistisches Problem ist in den letzten 40 Jahren so intensiv untersucht worden.
- Manipulation geschieht am häufigsten durch Sprache.
- Nichts behindert die internationale Kommunikation so sehr wie Sprachbarrieren.
- Was sich mit Sprache ausdrücken lässt, kann nur sehr schwer mit anderen Mitteln repräsentiert werden.
- Wer nicht richtig weiß, wie Sprache funktioniert, kann auch nicht richtig schreiben, sprechen, verstehen.
Daraus ergeben sich folgende Anforderungen für die Entwicklung (und zum Teil auch für die Benutzung) von Informationssystemen:
Man muss
- bewusster mit Sprache umgehen
- untersuchen, welche Rolle Sprache in der Prozesskette „Daten-Wissen-Information“ spielt
- die verschiedenen Ebenen sprachlicher Repräsentation verstehen
- verstehen lernen, warum mangelhafte Sprachverwendung die Kommunikation behindert
- Methoden zur Überwindung von Sprachbarrieren kennen lernen
- formale Herangehensweisen und Regel-/Gesetzmäßigkeiten beachten
In der Informationslinguistik geht es um die natürlichsprachigen Schnittstellen zwischen Mensch und System, die Übergänge zwischen Text und Wissen, die Transformation von Wissen in Information, Umwandlung von komplexen Aussagen in einfache, Formulierung und Analyse von Anfragen an Wissenssammlungen, sprachliche Repräsentation von Begriffen und formale Repräsentation von Sachverhalten, u.a.m. Einige dieser Aspekte sollen im Folgenden beleuchtet werden.
Begriff – Benennung – Text – Wissen
Den obigen Zusammenhang illustriert eine formale Darstellung von Gerhard Rahmstorf (das „magische Quadrat der Wissensorganisation“, vgl. Rahmstorf (1997): Der eigene Kern der Dokumentation im Wandel der Technik. In: Nachrichten für Dokumentation 48, 195-203, 1997), die das Verhältnis Begriff – Benennung – Text – Wissen einleuchtend darstellt und die im nachfolgenden eingehend erläutert wird.
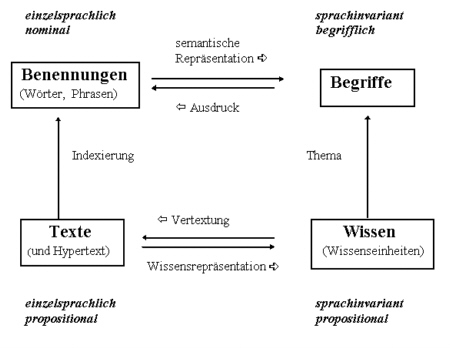
Wir wollen zunächst einen vertikalen Schnitt durch die Graphik machen. Dann bezieht sich die linke Hälfte auf einzelne Sprachen, also das, was von Sprache zu Sprache verschieden ist, nämlich Benennungen (die Wörter der Sprache) und Texte. Auf der rechten Seite steht dann das, was sprachunabhängig (sprachinvariant), also in allen Sprachen gleich ist, nämlich Begriffe und Wissen. Links steht also quasi das, was geschrieben und gesprochen werden kann (Sprachäußerungen), rechts dessen Bedeutung.
Der horizontale Schnitt teilt die Graphik in einen oberen Teil, der sich auf Einzelwörter und Begriffe (Nomina und Nominalphrasen) bezieht, und einen unteren, in dem es um Propositionen, also Aussagen geht.
Mit diesem Inventar lassen sich Wissens- und Informationseinheiten darstellen. Eine Wissenseinheit (also eine Proposition) ist z.B.: Der Löwe ist ein Säugetier. Ein Text besteht (in der Regel) aus mehreren Propositionen und hat eine eigene Struktur und bestimmte Eigenschaften, die ihn zum Text machen. Begriffe sind sprachlich noch nicht repräsentierte Vorstellungen, Konzepte, Ideen, die erst durch Benennungen (Nomina oder Nominalphrasen) einer natürlichen Sprache „konkret“, d.h. aussprechbar werden. So haben wir eine Vorstellung von einem bestimmten afrikanischen Raubtier, dessen männliche Exemplare eine Mähne tragen, das wir mit der Benennung Löwe belegen.
Wenn man nun die vier „Säulen“ Begriff – Benennung – Text – Wissen miteinander in Beziehung setzt, ergeben sich die verschiedenen Tätigkeiten des Bereichs „Information und Dokumentation“, die man grob in die beiden Bereiche „Textproduktion“ und „Texterschließung“ unterteilen kann.
Textproduktion beinhaltet zwei Teilprozesse (in der Graphik mit der Richtung „rechts-links“ angedeutet):
- „Ausdruck“: die Begriffe, um die es gehen soll, müssen mit Namen (Benennungen) belegt werden.
- „Vertextung“: Wissenseinheiten werden durch Vertextung zu Text.
Die Texterschließung bedingt drei Teilprozesse (Richtung „links-rechts“ bzw. „von unten nach oben“):
- „Semantische Repräsentation“: Benennungen werden durch Begriffe semantisch repräsentiert
- „Wissensrepräsentation“: Texte werden durch Methoden der Wissensrepräsentation in Form von Wissenseinheiten formalisiert dargestellt (vgl. den Beitrag zu Wissensrepräsentation und -organisation )
- „Indexierung“: Texten werden Benennungen (Deskriptoren) zugeordnet, die den Inhalt der Texte grob beschreiben.
Konsequenzen für Information und Dokumentation
Aus dem bisher Gesagten ergeben sich folgende Konsequenzen für den Bereich Information und Dokumentation: Überall dort, wo es um (Text-/Ton-)Dokumente in natürlicher Sprache geht, sind (intellektuelle und automatische bzw. computergestützte) Verfahren erforderlich, die
- Dokumente in einer geeigneten Form repräsentieren, so dass sie gespeichert und mit geeigneten Verfahren wiedergefunden werden können (Informations- oder Texterschließung)
- in welcher Form auch immer gespeichertes Wissen (Begriffe) in natürliche Sprache umwandeln, damit es (wieder-)verwendet werden kann (Textproduktion)
Ersteres kann bis zu einer gewissen Komplexitätsstufe durch automatische Verfahren erreicht werden. Hierzu gehört vor allem die automatische Indexierung, die in sehr unterschiedlicher Form eingesetzt wird, heute besonders auch für die Erschließung des WWW. Alles, was darüber hinaus geht, ist in der Regel nur eingeschränkt einsetzbar. Komplexe Dokumentbeschreibungen wie z.B. Abstracts (Zusammenfassungen) und Inhaltsanalysen werden derzeit nur intellektuell erstellt. Hier sind Computerlinguistik und Künstliche Intelligenz aufgefordert, geeignete Methoden und Verfahren zu entwickeln, die die intellektuellen Texterschließungsmethoden zumindest teilweise ersetzen.
Letzteres (die Textproduktion) umfassend zu automatisieren fällt in den Bereich der Science Fiction (vgl. z.B. HAL in ‚2001 – A Space Odyssey‚).
Teilbereiche der Informationslinguistik und Verbindungen zu anderen Disziplinen
Folgende Teilbereiche werden auf einer eigenen Seite kurz beschrieben und im Zusammenhang dargestellt:
- Information Retrieval
- Textproduktion
- Maschinelle und intellektuelle Indexierung
- Dokumentationssprachen
- Wissensrepräsentation
- Automatische Spracherkennung
- Morphologische Analyse
- Syntaktische Analyse
- Semantische Analyse
- Pragmatische Analyse
- Textanalyse (Inhaltserschließung)
- Masch. Übersetzung
- Lexika/Lexikondatenbanken
- Expertensysteme
- Information Extraction
- Kognitive Linguistik
- Hypertext
- Natürliche Sprache und das Internet
Fazit
Ziel dieser Webseite konnte es nur sein, eine einfache Sicht auf einen äusserst komplexen Zusammenhang darzustellen, der Teilgebiete der Informationswissenschaft, der (Computer-)Linguistik und der Künstlichen Intelligenz betrifft.
Weitere Literatur und Links
- Institut für Deutsche Sprache (1998-2004): Deutsche Rechtschreibung: Regeln und Wörterverzeichnis. Amtliche Regelung..
- http://www.ids-mannheim.de/reform/ , (9.11.2004)
- Institut für Deutsche Sprache (2004): grammis – das grammatische Informationssystem des IDS.
- http://hypermedia.ids-mannheim.de/index.html, (9.11.2004)
- Language Technology World (2004) – Das Sprachtechnologie-Portal.
- http://www.lt-world.org/, (9.11.2004)
- Arnold Stark (1997-2004): Unwörter.
- http://www.arnoldstark.de/dunwort.htm, (9.11.2004)
- Storrer, Angelika; Sandra Waldenberger (1998): Zwischen Grice und Knigge: Die Netiketten im Internet.
- http://www.ids-mannheim.de/grammis/orbis/net/netfram1.html, (9.11.2004)