
Studium Informationswissenschaft
Virtuelles Handbuch Informationswissenschaft
8. Informationswissenschaft als Brückenwissenschaft
Exkurs: Informationslinguistik
Heinz-Dirk Luckhardt

Was haben Information und Sprache
miteinander zu tun?
Grob skizziert stellt sich der gesamte Ablauf von Textproduktion und Informationsgewinnung folgendermaßen dar.
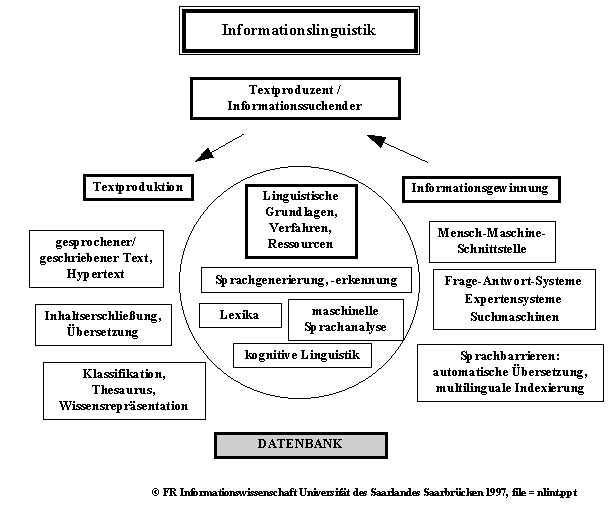
| Zu den einzelnen Teilbereichen der Informationslinguistik gibt es eine eigene Sektion |
Textproduktion: Es werden geschriebene oder gesprochene Texte bzw. Hypertexte produziert, die in ein Informationssystem eingebracht werden sollen. Gesprochene Texte durchlaufen ein Spracherkennungsmodul (speech recognition) und werden so zu geschriebenen, bevor sie weiterverarbeitet werden. Alle Texte müssen in elektronischer Form vorliegen, wenn sie durch elektronische Verfahren weiterverarbeitet werden sollen, d.h. sie werden gleich elektronisch erfaßt oder mithilfe von OCR-Scannern (Optical Character Recognition) in elektronische Form gebracht. Die Frage des Formats solcher Texte spielt eine erhebliche Rolle, da die verschiedenen Textprozessoren verschiedene Formate ausgeben, die i.d.R. nicht miteinander kompatibel sind. Ausnahmen sind hier bestimmte Arten normierter Texte.
- ASCII-Text (American Standard Code for Information Interchange):
- von jedem Textprozessor ausgebbarer normierter primitiver Text ohne jede Auszeichnung (Unterstreichung, Fettdruck, Absätze…).
- SGML (standard generalized mark-up language):
- In der ISO-Norm 8879 ist genau festgelegt, wie Texte nach der SGML ausgezeichnet werden. Dies ist eine Schnittstelle für den Austausch von Textdaten zwischen verschiedenen Informationssystemen. Die gängigen Textprozessoren berücksichtigen diese Möglichkeit aber noch nicht.
- HTML (hypertext mark-up language):
- Ausgehend von der SGML stellt die HTML die gemeinsame Grundlage aller Worldwide-Web-Dokumente dar.
Bevor Texte in ein Informationssystem eingebracht werden, muß man sie „erschließen“. Dabei werden sie so aufbereitet, daß man sie später beim eigentlichen Prozeß der Informationsrecherche „wiederfindet“ (Information Retrieval, [ritri:vl]). Diese Erschließung geschieht formal und inhaltlich. In der formalen Dokumentanalyse werden Standarddaten wie Autor, Titel, Erscheinungsort und -jahr etc. erfaßt. Die inhaltliche Erschließung ist das zentrale Problem der Informationslinguistik, nämlich die Beschreibung des Inhalts von Dokumenten durch maschinelle ((semi-)automatische Indexierung) oder intellektuelle Verfahren.
Hierunter sind v.a. die Indexierung, die Klassifizierung und das Abstracting zu verstehen. Bei der Indexierung werden (automatisch oder intellektuell) inhaltsbeschreibende Begriffe vergeben, die dem Text selbst entstammen (Stichwörter) oder zusätzlich hinzugefügt werden (Schlagwörter). Diese Deskriptorenvergabe kann insofern Restriktionen unterliegen, als für die inhaltliche Beschreibung einer Textsammlung oft Sprachregelungen getroffen werden, die eine Einheitlichkeit der Beschreibung zum Ziel haben. Beim Abstracting wird der Text kurz zusammengefaßt, Ergebnis ist ein „Referat“, auch „Abstract“ oder „Zusammenfassung“ genannt. Beim Klassifizieren wird der vorliegende Text einer Klasse aus der für das betreffende Fachgebiet maßgeblichen Klassifikation zugeordnet, z.B. erhalten Patentschriften eine oder mehrere kennzeichnende Klassen (aus der Int. Patentklassifikation IPC).
Insbesondere bei der automatischen Indexierung werden linguistische Verfahren eingesetzt, die eine umso tiefere sprachliche Analyse erfordern, je komplexer die Beschreibung sein soll. Hier sind die Morphologie (Flexion, Wortbildung, Wortzusammensetzung), die Syntax und die Semantik zu nennen. Gemeinsam ist diesen Verfahren der Zugriff auf Lexika, die die notwendigen Informationen über die Analyse von Wörtern und den Aufbau komplexerer Strukturen aus Wörtern (Nominalgruppen, Sätze) enthalten.
Zur inhaltlichen Beschreibung werden Dokumentationssprachen verwandt. Dazu gehören neben den Klassifkationen die Thesauri (zur Beziehung zwischen Klassifikationen/Thesauri und der Verarbeitung natürlicher Sprache), in denen die zur Inhaltsbeschreibung zulässigen Benennungen („Vorzugsbenennungen“) zusammengefaßt sind und die darüberhinaus ein ganzes Geflecht von Beziehungen (Synonymie, Unter- + Oberbegriff, Ähnlichkeit) zwischen verwandten Begriffen und Benennungen enthalten, das einerseits die konsistente Vergabe von Deskriptoren und andererseits später die leichtere Formulierung von Suchfragen an das System ermöglichen soll. Im weitesten Sinne sind diese Inhaltsbeschreibungen der Wissensrepräsentation zuzuordnen, wie sie in der Künstlichen Intelligenz und der Kognitiven Linguistik erforscht wird. (vgl. den Beitrag zu Wissensrepräsentation und -organisation).
Neben der Inhaltserschließung ist die (maschinelle) Übersetzung von Dokumenten ein weiterer informationeller Mehrwert, der die Zugreif- und Nutzbarkeit von Textdokumenten erhöht. Hier handelt es sich um ein wichtiges Gebiet der computerlinguistischen Forschung und Entwicklung, auf dem die Universität des Saarlandes seit dem Ende der 60er Jahre immer eine wichtige Rolle gespielt hat und noch spielt (vgl.: >SUSY, externe Links: EUROTRA, Verbmobil).
Die so erschlossenen Textdokumente werden in Datenbanken, den zentralen Wissensspeichern der Informationssysteme, gesammelt, von denen es die verschiedensten Arten gibt, worauf hier nicht eingegangen werden soll.
Informationsgewinnung: Der eigentliche Zweck von Informationssystemen ist das Information Retrieval (Informations(wieder)gewinnung). Auch hier spielen sprachliche Prozesse eine Rolle, die Teil der Benutzerschnittstelle (Mensch-Maschine-Schnittstelle) sind, über die ein Systembenutzer mit einem Informationssystem kommuniziert. Dies z.B. dann, wenn das System über eine natürlichsprachliche Schnittstelle verfügt, über die Anfragen in der Sprache des Informationssuchenden eingegeben werden können. Dazu gehören dann komplexe Analyseprozeduren, wie sie im Prinzip auch bei der Maschinellen Übersetzung und der automatischen Indexierung zum Einsatz kommen können. Solche Systeme können z.B. Frage-Antwort-Systeme, die Anfragen an Faktenbanken verarbeiten können, Expertensysteme (wissensbasierte Systeme), die über Fachwissen in Form von Wissensbasen verfügen, oder natürlichsprachliche Front-Ends von Datenbanken sein, über die Benutzer Anfragen in natürlicher Sprache formulieren können.
Aus Sicht der Informationswissenschaft spielt in diesem Zusammenhang besonders die Formulierung von Suchfragen an Datenbanken im Zuge des eigentlichen „Information Retrieval“ eine große Rolle. Hier kommt es v.a. auf die „Suchsprachen“, die das jeweilige Informationssystem bietet, sowie die oben schon erwähnten Thesauri an, die dem Benutzer Aufschluß über die erfolgversprechendsten Suchbegriffe geben.
Fazit: Da es in Informationssystemen i.d.R. um sprachlich formuliertes Wissen geht, ist die Verarbeitung natürlicher Sprache ein zentraler Bereich der Informationswissenschaft (Informationslinguistik). Dies ist gerade in einer Zeit besonders virulent geworden, in der das Worldwide Web ins Zentrum des Interesses gerückt ist. Die dort bisher realisierten Verfahren der Informations(wieder)gewinnung (Suchmaschinen) machen nämlich deutlich, daß es hier keine besonders effektiven Möglichkeiten der Informationsrecherche gibt (vgl. Luckhardt 1996); und gerade hier – in der größten aller denkbaren Wissensmengen – sind solche Möglichkeiten dringend vonnöten.
Weitere informationslinguistische Beiträge auf diesem Server:
- Informationsdesign von Texten
- Hypertext
- Dokumentationssprachen
- Wissensrepräsentation und -organisation
- Automatische Indexierung
- Maschinelle Übersetzung
- Thesauri und Klassifikationen in der Verarbeitung natürlicher Sprache
- Information Retrieval
Einige externe WWW-Quellen zur Informationslinguistik
- The Language Technology Research Center: www.multilingual.com
- http://www.multilingual.com/
- SUSY – Maschinelle Übersetzung
- http://www.is.uni-sb.de/projekte/sonstige/natlangs/susytest.html
- SYSTRAN – Free Online Translation
- http://www.systransoft.com/
- Natural Language Processing: Professional Associations
- http://www.ims.uni-stuttgart.de/info/SIGs.html
- Interactive online CL Demos
- http://www.ifi.unizh.ch/CL/InteractiveTools.html
- Language Technology World (2004) – Das Sprachtechnologie-Portal.
- http://www.lt-world.org/, (9.11.2004)
- The Linguist List.
- http://www.linguistlist.org/
- Survey of the State of the Art in Human Language Technology
- http://cslu.cse.ogi.edu/HLTsurvey/
- http://is.uni-sb.de/studium/handbuch/:
- u.a. Automatische und intellektuelle Indexierung, Information Retrieval, Informationslinguistik, Disambiguierung, Hypertext, Maschinelle und computergestützte Übersetzung von Fachinformation, Thesauri und Klassifikationen und die Verarbeitung natürlicher Sprache
Literatur:
- Antos, G.; H.P. Krings (Hrsg., 1989):
- Textproduktion. Ein interdisziplinärer Forschungsüberblick. Tübingen: Niemeyer
- Bekavac, B. 1996):
- Suchverfahren und Suchdienste des Worldwide Web. In: Nachrichten für Dokumentation 4/96, 195-213
- Buder, M.; W. Rehfeld; T. Seeger, D. Strauch (Hrsg., 1997).
- Grundlagen der praktischen Information und Dokumentation. München et al.: K.G. Saur
- DIN 1463.
- Erstellung und Weiterentwicklung von Thesauri. Teile 1 und 2. Berlin 1988
- DIN 31623.
- Indexierung zur inhaltlichen Erschließung von Dokumenten. Berlin 1988
- Knorz, G. (1997).
- Indexieren, Klassieren, Extrahieren. In: Buder/Rehfeld/Seeger/Strauch (Hrsg., 1997)
- Krause, J. (Hrsg., 1987).
- Inhaltserschließung von Massendaten. Zur Wirksamkeit informationslinguistischer Verfahren am Beispiel des Deutschen Patentinformationssystems. Hildesheim et al.: Olms
- Kuhlen, R. (1997).
- Abstracts – Abstracting – intellektuelle und maschinelle Verfahren. In: Buder/Rehfeld/Seeger/Strauch (Hrsg., 1997)
- Luckhardt, H.-D. (1987).
- Der Transfer in der Maschinellen Sprachübersetzung. Sprache und Information Band 18. Tübingen: Niemeyer
- – (1992).
- Thesauri für die Maschinelle Übersetzung. In: H.H. Zimmermann, H.-D. Luckhardt, A. Schulz (Hrsg., 1992). Mensch und Maschine – Informationelle Schnittstellen der Kommunikation. Schriften zur Informationswissenschaft Band 7 Konstanz: Universitätsverlag
- – (1996):
- Das WWW als Infomedium. http://is.uni-sb.de/studium/handbuch/infomediumwww. 20.3.97
- Lustig, G. (Hrsg., 1986).
- Automatische Indexierung zwischen Forschung und Anwendung. Hildesheim et al.: Olms
- Maly, Frank (1990).
- Zur Leistungsbewertung automatischer Indexierungsverfahren. Ms. Abschlußarbeit. Lehrinstitut für Dokumentation (LID). Frankfurt
- Panyr, J. (1986).
- Automatische Klassifikation und Information Retrieval. Tübingen: Niemeyer
- Panyr, J.; H.H. Zimmermann (1989).
- Information Retrieval: Aktive Systeme und Entwicklungen. In: Batori/Lenders/Putschke Hrsg., 1989), 696-708
- Salton, G.; M.J. McGill (1987).
- Information Retrieval. Hamburg et al.
- Schwarz, C.; G. Thurmair (Hrsg., 1986).
- Informationslinguistische Texterschließung. Hildesheim et al.: Olms
- Wersig, G. (1985).
- Thesaurus-Leitfaden. Eine Einführung in das Thesaurus-Prinzip in Theorie und Praxis. München et al.: K.G. Saur
- Zimmermann, H.H.; E. Kroupa; G.C. Keil (Hrsg., 1983).
- CTX – Ein Verfahren zur computergestützten Texterschließung. Forschungsbericht ID 83-006 Information und Dokumentation des BMFT. Karlsruhe: FIZ Karlsruhe. Auch in: Veröffentlichungen der Fachrichtung Informationswissenschaft. Saarbrücken: Universitätdes Saarlandes
- Zimmermann, H.H. (Hrsg., 1987).
- Der Transfer informationslinguistischer Technologien am Beispiel von CTX und ITS. Veröffentlichungen der FR Informationswissenschaft. Saarbrücken: Universität des Saarlandes