
Identität und Geschichte der Informationswissenschaft
Information und Sprache
Thema:Information und Sprache
Projekte: Identität und Geschichte der Informationswissenschaft
I.Einführung
I.I Die Bedeutung der Sprache für den Menschen
Die Sprache ist das wichtigste Kommunikationsmittel des Menschen. Auch bei der wachsenden Zahl multimedialer Informationsangebote bleibt sie die bedeutendste Methode der Informationsvermittlung. Wissen wird nahezu immer in sprachlicher Form übermittelt: denken wir an den Schulunterricht, an Vorlesungen, Bücher, Zeitschriften, Datenbanken, das WWW. Auch die meisten Retrievalsysteme arbeiten mit natürlichsprachlichen Eingabemasken. Für den Existenzphilosophen Martin Heidegger ist das Wort „Sprache“ kennzeichnend für unser Zeitalter. Für ihn bedeutet „Sprache“ „‚einmal die unmittelbare Benachrichtigung und Meldung‘ zugleich und zum anderen ‚die unauffällige Prägung (Formierung) der Leser und Hörer'“ (Capurro:2000:Heidegger über Sprache und Information). Der Mensch wird am häufigsten durch Sprache manipuliert, rufen wir uns nur einmal die einprägsamen Slogans der täglich auf uns einprasselnden Werbe-Spots ins Gedächtnis. Wie wichtig Sprache ist, merken wir oft erst dann, wenn sich auf dem sprachlichen Gebiet Schwierigkeiten ergeben. Die internationale Kommunikation wird in starkem Maße durch Sprachbarrieren behindert, was z.B. durch die Tatsache illustriert wird, dass es auf der Welt rund 5500 Einzelsprachen gibt
I.II Das sprachliche Zeichen
Der Sprachwissenschaftler Ferdinand de Saussure untergliedert das Sprachsystem (langue) in Einheiten (= sprachliche Zeichen) und Relationen. Nach de Saussures Zeichentheorie ist das sprachliche Zeichen bilateral, d.h., es besitzt, einem Blatt gleich, zwei Seiten, die nicht voneinander zu trennen sind. Es sind: das Bezeichnete (signifié), das, was bezeichnet wird, also die Vorstellung, die in unseren Köpfen von etwas Bestimmtem aus der extralinguistischen Welt existiert, und das Bezeichnende (signifiant), also das Lautmuster, mit dem wir diese Vorstellung ausdrücken. In der Informationswissenschaft spricht man hier von Begriff und Benennung. Ein sprachliches Zeichen ist durch die folgenden beiden Relationen gekennzeichnet: Die erste Relation ist die der Arbitrarität (Willkürlichkeit): Bezeichnetes und Bezeichnendes haben keine Eigenschaften, die eine bestimmte Zuordnung bedingen. Um ein Beispiel zu nennen: Es gibt keinen Grund, warum wir ein Tier, das fliegen kann und ein Federkleid besitzt, mit dem Lautmuster [fo:gl] bezeichen.
Die zweite Relation ist die der Konventionalität. Das heißt, über die Beziehung zwischen signifiant und signifié muss in der Alltagssprache eine implizite Übereinkunft bestehen, in den Fach- und Wissenschaftssprachen sogar eine explizite Übereinkunft. Wir müssen für ein und dieselbe Sache konsequent dieselbe Bezeichnung wählen, sonst ist Kommunikation nicht möglich. Die Summe der sprachlichen Zeichen ist der in unserem Gedächtnis gespeicherte Wortschatz.

I.III Der Zusammenhang zwischen Begriff, Benennung, Text, Wissen
Wenn wir über etwas nachdenken, uns mit jemand anderem unterhalten oder etwas schriftlich formulieren, setzen wir die sprachlichen Zeichen zueinander in Beziehung. Wir reihen nicht einfach nur Einzelwörter aneinander, sondern bilden – auf der signifiant-Ebene – Sätze, deren Bestandteile sich aufeinander beziehen (Bsp.: Anpassung eines Adjektivs an das nachfolgende Substantiv). Mehrere zueinander kohärente Sätze bilden einen Text. Für die signifié-Ebene bedeutet dies: Wir haben es nicht mehr nur einfach mit Vorstellungen zu tun, sondern mit ganzen Wissenseinheiten. Den Zusammenhang zwischen Begriff, Benennung, Text, Wissen wird sehr gut veranschaulicht durch die „formale Darstellung von Gerhard Rahmstorf (das ‚magische Quadrat der Wissensorganisation‘, vgl. Rahmstorf (1997): Der eigene Kern der Dokumentation im Wandel der Technik. In: Nachrichten für Dokumentation 48, 195-203, 1997)“ (Luckhardt:2000: Die Bedeutung von Sprache für die Entwicklung und Nutzung von Informationssystemen):
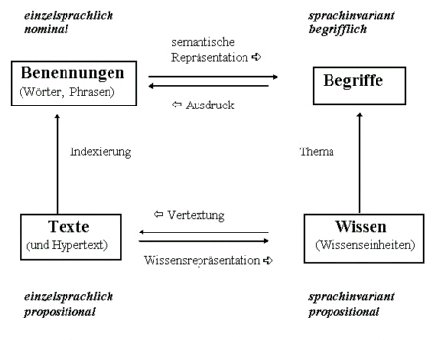
Die linke Hälfte der Grafik – welche der signifiant-Ebene entspricht (= Benennungen) – ist von Sprache zu Sprache verschieden: Für denselben Begriff, dasselbe signifié, gibt es in verschiedenen Sprachen verschiedene signifiants (Bsp. „Tier, das fliegen kann und ein Federkleid besitzt“: deutsch: „Vogel“, französisch „oiseau“, englisch: „bird“). Auch ganze Texte liegen in verschiedenen Sprachen vor. Die rechte Seite des Schaubilds – welche der signifié-Ebene entspricht (= Begriffe) – ist sprachunabhängig.
Dieses Schema gibt Aufschluss über die verschiedenen Aufgaben, die der Informationswissenschaft auf dem Teilgebiet „Information und Sprache“ zufallen und die sich in die Unterbereiche Textproduktion und Texterschließung untergliedern lassen.
I.IV. Textproduktion
Die Textproduktion ist der Erstellungsprozess von Texten. Sie umfasst gesprochene und geschriebene Texte. Um ein elektronisches Informationssystem entwickeln zu können, muss das sprachliche Material in elektronischer Form vorliegen. Gesprochene Texte müssen dafür erst ein Spracherkennungsmodul durchlaufen, geschriebene müssen, wenn sie noch nicht digitalisiert vorliegen, mit Hilfe des OCR-Vefahrens (OCR = Optical Character Recognition) umgewandelt werden. Im Vorfeld der Textproduktion muss man sich überlegen, welche Textart man produzieren will. Möchte man einen linearen Text herstellen, der sich aus einer chronologischen Abfolge von Sätzen, Abschnitten, Seiten bzw. einer Abfolge von zueinander kohärenten Propositionen zusammensetzt? Oder will man einen Hypertext produzieren, also einen Kerntext mit Querverweisen (Links) innerhalb des Textes oder auf andere Texte? Beide Vorgehensweisen haben eine spezifische Problematik. Beim Lesen eines linearen Textes – beispielsweise eines Buches – ist man gezwungen, dem vom Autor vorgegebenen Gedankenfluss zu folgen. Überspringt man einfach ein oder zwei Kapitel, kann es passieren, dass man den Zusammenhang verliert. Bei einem Hypertext hingegen kann der Leser die Art des Rezipierens selbst bestimmen, er kann z.B. erst den Text linear durchlesen und später die Links verfolgen. Er kann aber auch gleich während der Lektüre jeden Link anklicken. Darüberhinaus kann er Themen, die ihn nicht interessieren, auslassen, ohne dabei den Zusammenhang zu verlieren. Gefahr dabei jedoch ist, dass er früher oder später die Übersicht verliert („Lost in hyperspace“). Die besondere Aufgabe des Hypertextautors ist, die einzelnen Hypertexteinheiten so zu konstruieren, dass die geschilderten Rezeptionsarten tatsächlich möglich sind und die möglichen Probleme für die Hypertextleser gering gehalten werden.
Hauptschwierigkeit bei der Produktion von Hypertexten ist also das „das sogenannte ‚Authoring‚, das eigentliche Konstruieren des Hypertextes“ (Luckhardt:2000:Hypertext – eine erste Orientierung) [Hervorhebung: J.T.]. Probleme treten besonders dann auf, wenn ein linear verfasster Text in Hypertext umgewandelt werden soll. „Inhaltlich gesehen ist es oft schwierig, einen längeren Text in ‚handliche‘ Informationseinheiten (‚chunks‘) zu zerlegen (‚chunking‘) und zwischen ihnen Verbindungen zu knüpfen (‚linking‘). Hierfür existieren noch keine theoretischen Konzepte. Besonders bei argumentativen Texten oder Texten, in denen ein Gedanke über längere Zeit (mehrere Seiten hinweg) verfolgt wird, ist das Chunking schwierig bis unmöglich“ (ebd.). Der Autor muss jede dieser Informationseinheiten im Prinzip so aufbereiten, als stünde sie alleine, damit der Leser selbst beim Überspringen einiger Abschnitte den Zusammenhang nicht verliert.
I.V. Texterschließung
Bevor man einen fertig produzierten und elektronisierten Text in ein Informationssystem einbringt, muss er zuvor – damit man ihn bei einer späteren Recherche wiederfindet – inhaltlich erschlossen werden. Man unterscheidet zwei Formen der Texterschließung:
a) die formale Analyse
Man verzeichnet allgemeine Daten wie z.B. den Autor des Textes, den Titel, den Verlag, in dem der Text erschienen ist, das Erscheinungsjahr. Diese Vorgehensweise ist typisch für Bibliothekskataloge.
b) die inhaltliche Erschließung
Sie ist „das zentrale Problem der Informationslinguistik, nämlich die Beschreibung des Inhalts von Dokumenten durch maschinelle ((semi-)automatische Indexierung oder intellektuelle Verfahren. Hierunter sind v.a. die Indexierung, die Klassifizierung und das Abstracting zu verstehen“ (Luckhardt:2000:Informationslinguistik).
 zum Inhaltsverzeichnis | II.I.Was ist Informationslinguistik?
zum Inhaltsverzeichnis | II.I.Was ist Informationslinguistik? 